The Model Is No Longer the Moat: Governance Is

Most AI commentary still treats enterprise adoption as a capability problem. The buyers don't. When every model is good enough, the moat stops being performance and moves to what makes a system governable: auditable, controllable, replayable. And that moat lives in durable infrastructure, not in the model.
Here is the argument in plain English, faithful to the deck below: why the buying conversation changed, what "durable infrastructure" actually means, and why the model is becoming the most replaceable layer in the stack. The deck is the whole thing; the written breakdown follows.





The buying conversation moved
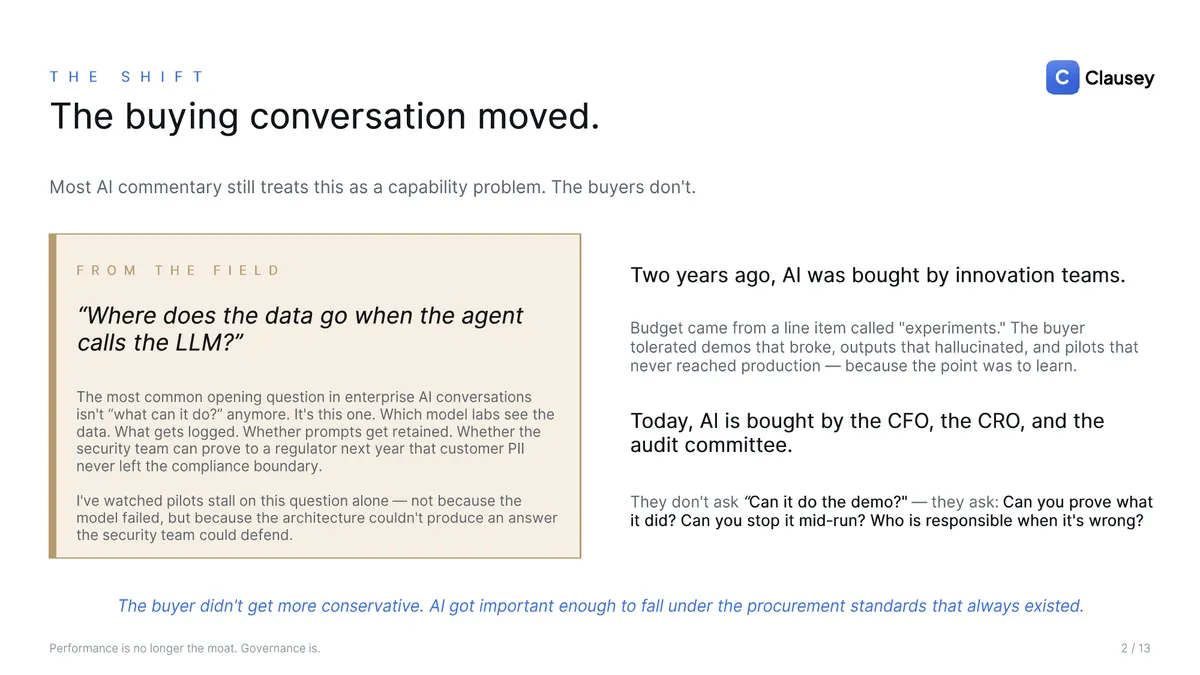
Two years ago, enterprise AI was bought by innovation teams, out of a budget line called "experiments." That buyer tolerated demos that broke, outputs that hallucinated, and pilots that never reached production, because the point was to learn. Today the same software is bought by the CFO, the CRO, and the audit committee, and they ask a different question. Not "can it do the demo?" but: can you prove what it did, can you stop it mid-run, and who is responsible when it's wrong? The most common opening question in enterprise AI is no longer "what can it do" — it's "where does the data go when the agent calls the LLM?" The buyer didn't get more conservative. AI simply got important enough to fall under the procurement standards that always existed.
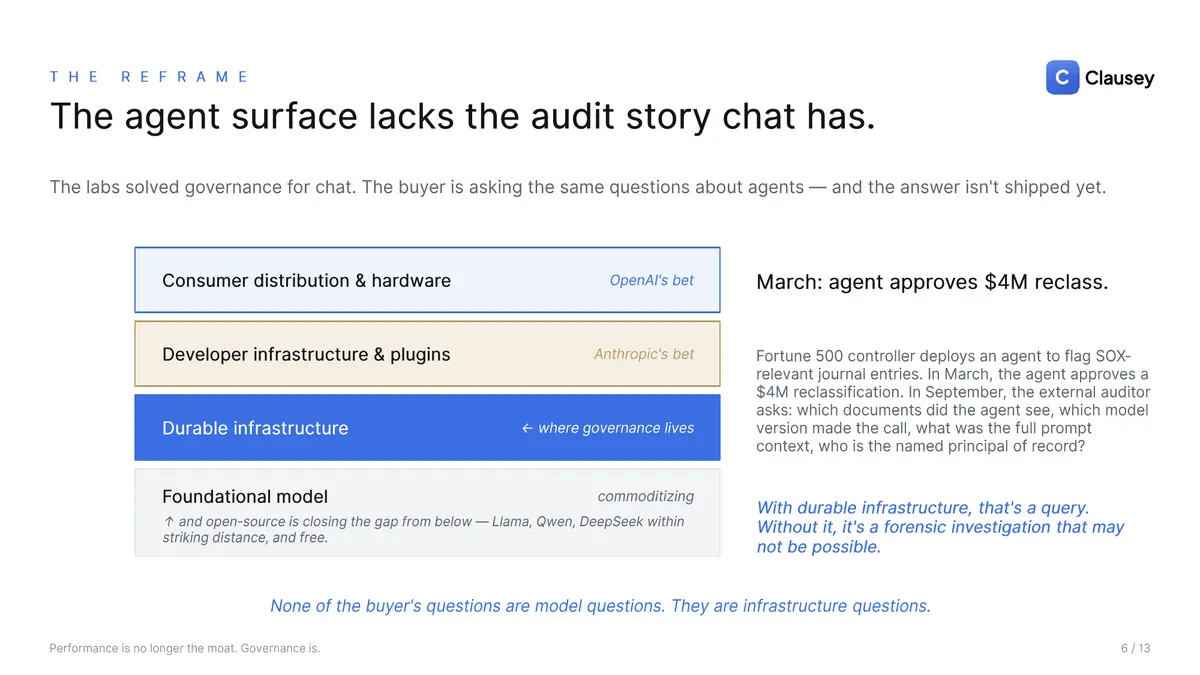
Capability got abundant, and commoditized
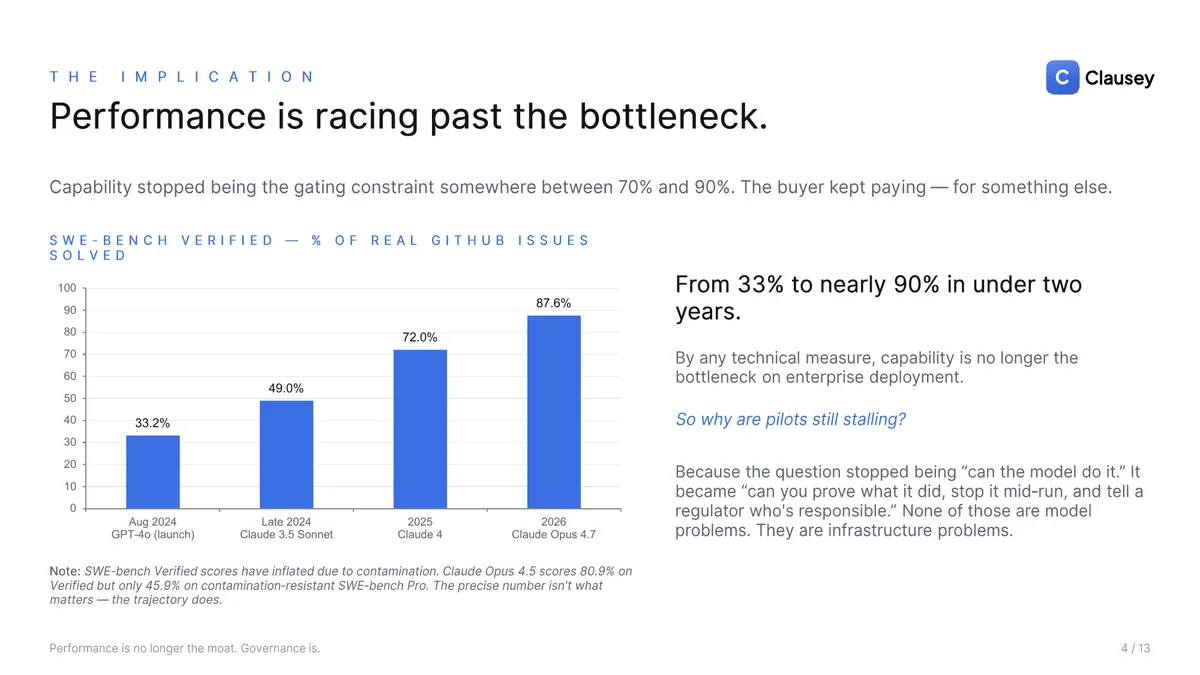
Three things are happening at once that, on paper, shouldn't. Models are racing toward frontier capability: SWE-bench Verified went from under 2% in late 2023 to roughly 87.6% in 2026. They are commoditizing just as fast — the gap between the frontier and "good enough for production" has collapsed, enterprises run multi-model deployments and swap providers mid-contract, and a five-point benchmark lead is matched within a quarter. And the open-source floor is rising underneath both: Llama, Qwen, and DeepSeek are within striking distance for most enterprise tasks, and they're free. (A caveat the deck makes itself: those benchmark numbers are inflated by contamination — the trajectory, not the precise figure, is the point.) Once "good enough" is free, paying frontier prices for marginal capability stops making sense, and the question shifts from "can the model do it" to "can you prove what it did." Pilots aren't stalling on capability anymore. They stall on questions that have no model-level answer.
Governance shipped for chat, not for agents
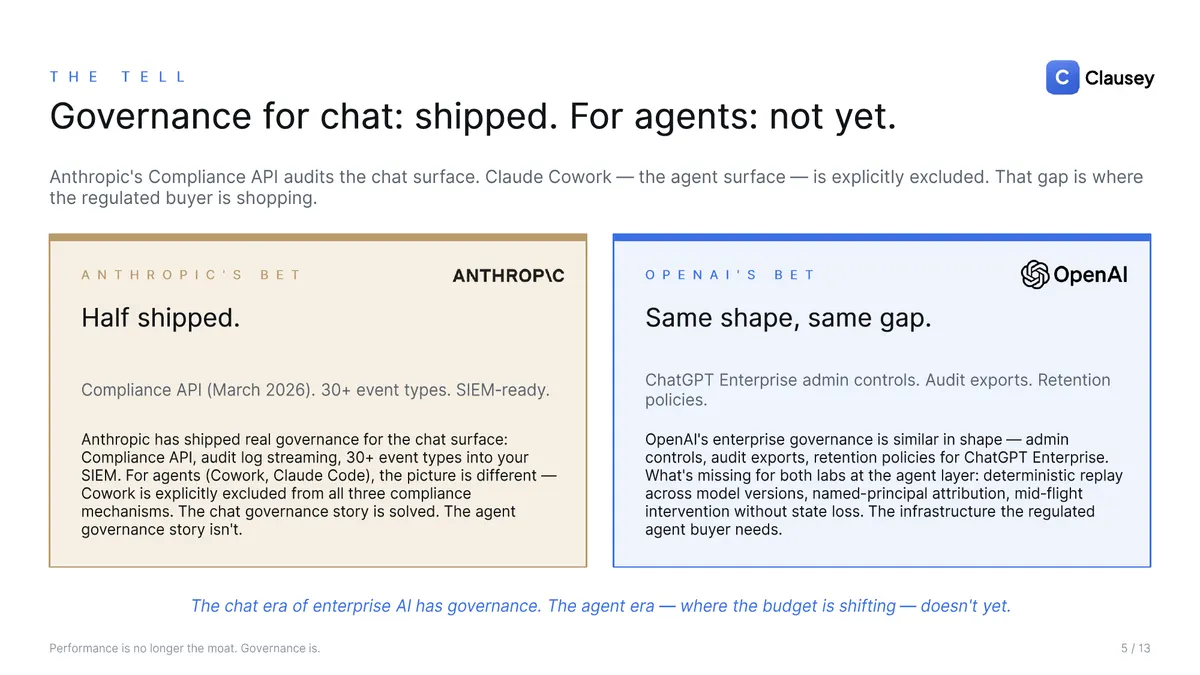
Here's the tell. The labs have shipped real governance for the chat surface: audit-log streaming, dozens of event types, SIEM-ready exports, retention controls. But the agent surface — the autonomous systems that take actions, where the enterprise budget is now shifting — is largely excluded from those same mechanisms. What's missing at the agent layer is specific: deterministic replay across model versions, named-principal attribution, and mid-flight intervention without losing state. The chat era of enterprise AI has a governance story. The agent era doesn't yet, and that gap is exactly where the regulated buyer is shopping.
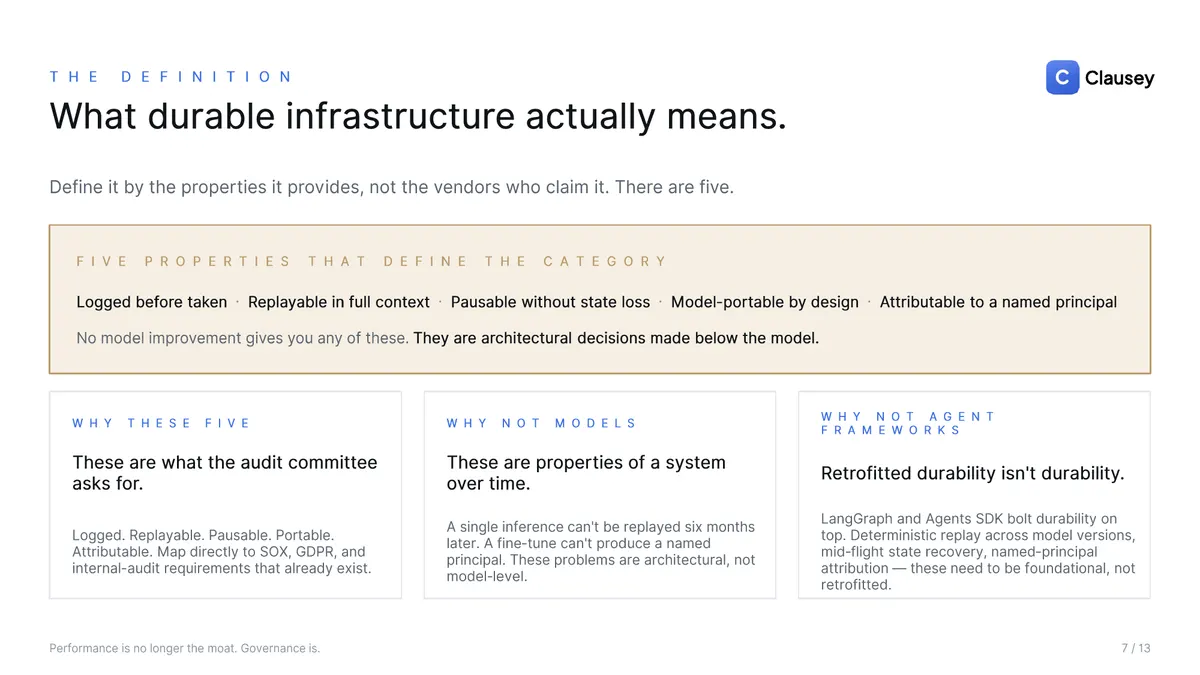
What "durable infrastructure" actually means
Define the category by the properties it provides, not the vendors who claim it. There are five: every action is logged before it's taken, replayable in full context, pausable without state loss, model-portable by design, and attributable to a named principal. No model improvement gives you any of these — they are architectural decisions made below the model. A single inference can't be replayed six months later; a fine-tune can't produce a named human being who is accountable. And retrofitted durability isn't durability: bolting replay and state recovery onto an agent framework after the fact leaves exactly the gaps an auditor finds — version drift, lost state, broken attribution. These properties have to be foundational.
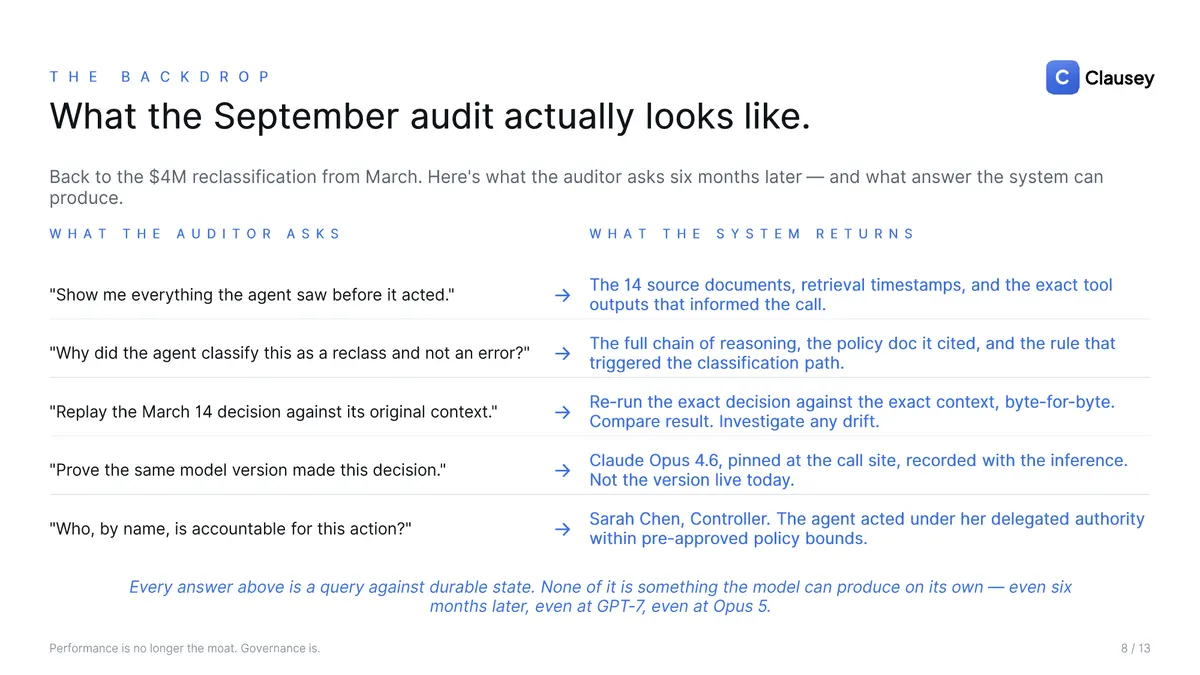
The September audit
Make it concrete. In March, a Fortune 500 controller deploys an agent to flag SOX-relevant journal entries, and it approves a $4 million reclassification. In September, the external auditor arrives and asks five questions: show me everything the agent saw before it acted; why did it classify this as a reclass and not an error; replay the March decision against its original context; prove the same model version made the call; and who, by name, is accountable. With durable infrastructure, every one of those is a query — the source documents and retrieval timestamps, the full chain of reasoning and the policy it cited, a byte-for-byte replay, the pinned model version recorded with the inference, and the named principal who held delegated authority. Without it, the same five questions are a forensic investigation that may not be possible. None of the answers are something the model can produce on its own — not six months later, not at GPT-7, not at Opus 5.
The model becomes config; the infrastructure becomes the moat
This is the inversion. Once durable infrastructure exists, the most expensive layer in the stack becomes the most replaceable. Today, swapping models re-validates the whole deployment; tomorrow it's a config change — you swap providers, run the suite, and watch the audit trail prove the new model behaves within tolerance. No re-architecture, no re-procurement, no new audit. Model choice becomes a regression test, a vendor decision rather than an architectural one. The moat moves to the layer that can't be swapped: the audit trail can't move, the replay history can't move, the named-principal mapping can't move — the model can. That asymmetry is the moat, and it accrues to whoever owns the layer that holds it. The model becomes a tool the infrastructure calls, not the other way around.
The bear case
Three things could make this wrong, and they're worth saying out loud. A frontier lab could build governance natively and make it model-portable — though model-portable governance is structurally odd for a model lab, since its whole point is to make the model swappable. The buyer could keep signing off without rigor, leaving governance a checkbox rather than a procurement gate — until the first material, agent-related restatement turns it into one. Or agent frameworks could retrofit "good enough" durability before the gap shows up in procurement — until the first real audit failure, in the version drift and broken attribution that retrofits leave behind, resets the category. The thesis holds if audit rigor becomes a procurement gate, not just a buying conversation. That's the bet.
Three questions to ask any AI agent vendor
If the answer to any of these is "we're working on it," you're buying a demo, not a system.
- Verifiability. Can you replay any decision the agent made six months ago against its original inputs? A good answer points to an immutable event log and a way to re-run a step. A bad one is "we log to a debugging tool."
- Controllability. Can a compliance officer pause a running agent mid-flight, indefinitely, without losing its state? A good answer is a gate where the run parks and resume picks up where it left off. A bad one is "we have a kill switch."
- Accountability. Who, by name, is accountable for an action the agent took on the company's behalf? A good answer is a named principal and a liability mapping. A bad one is "the agent is."
The model is the layer everyone is looking at. The infrastructure layer is the one that decides who wins.
Where Clausey fits
This is the layer Clausey is built on, and the AI-native engineering playbook we follow to build it. Every agent run is logged step by step as it happens, replayable and resumable after a crash or a deploy, tied to a named user under real role-based permissions, and designed so the model underneath is a swappable part, not the foundation. We point that durable infrastructure at your operations: Clausey reads your documents, structures them into data, answers with citations you can trace to the page, checks everything against your policies, and automates the work that follows — with the audit trail an enterprise buyer now asks for first.
Capability is abundant. What's scarce is a system you can prove. That's the moat.
Get the latest product news and behind the scenes updates.