How AI Agents Work Together: Subagents and Orchestrators

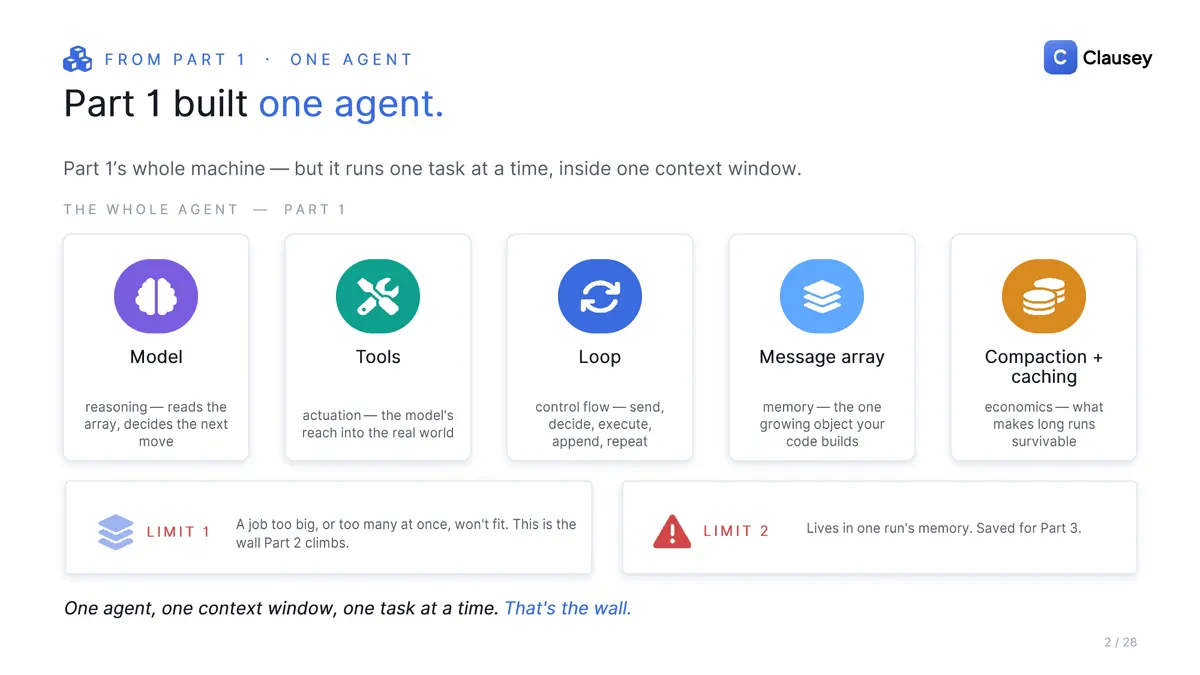
In Part 1 we built an AI agent down to the single API call: a model, in a loop, with tools. It works, but it does one task at a time, inside one context window, and that is a wall. The way through is one small idea with outsized consequences: one of an agent's tools can be another agent. That is all a "team" of agents really is.
This is Part 2, in plain English and faithful to the deck below: how agents work together, how to split a goal between them, and the handful of habits that keep a team from quietly corrupting its own work. Here is the whole thing as a scrollable deck, and the written breakdown follows.




A tool can be another agent
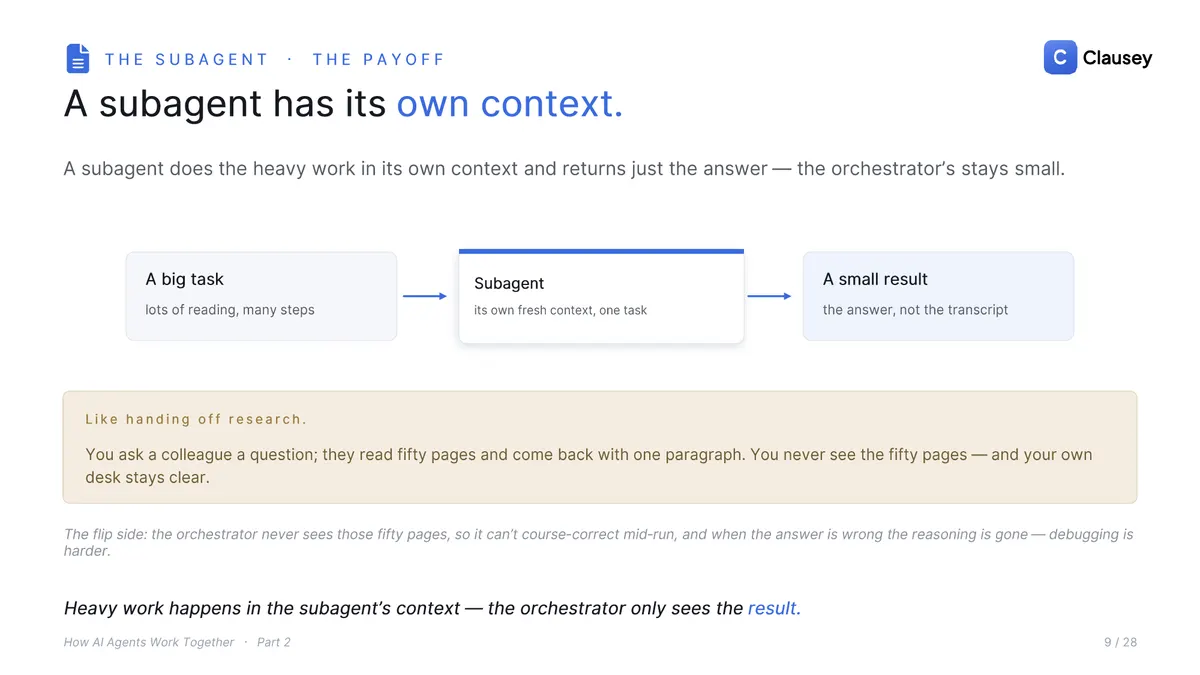
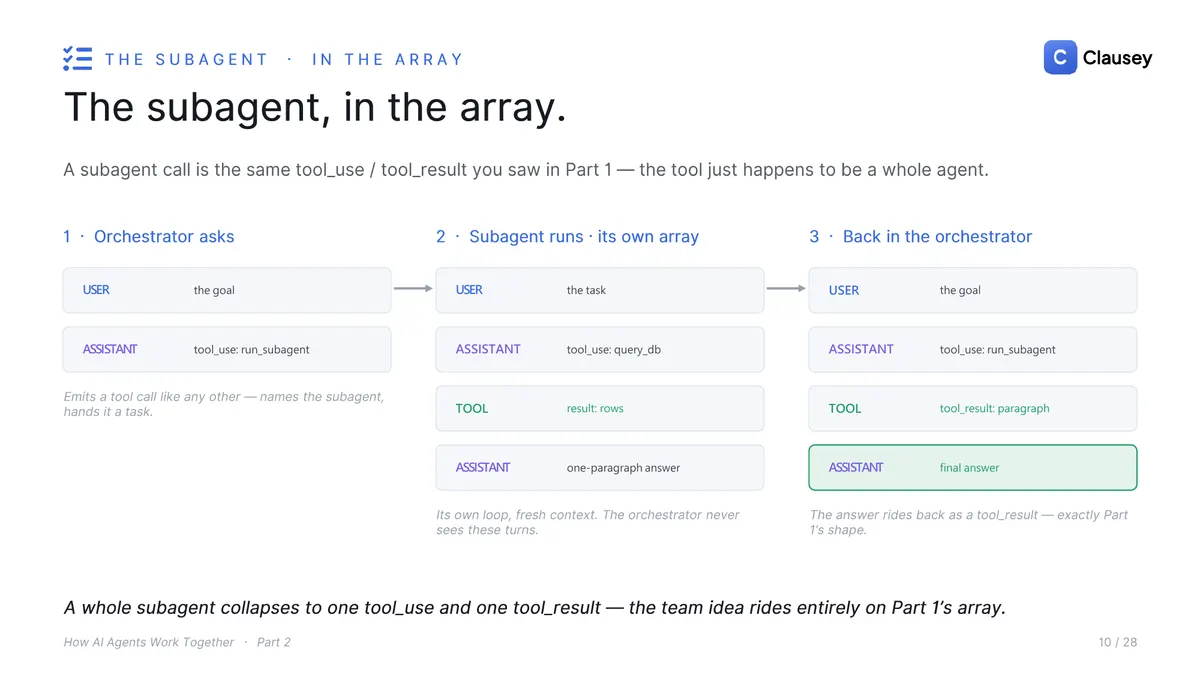
An agent already calls tools: you list what is available, the model emits a call, your code runs it, and the result goes back into the conversation. A subagent is just a tool whose job is to run another agent. The caller treats it like any other tool, but behind it sits a second agent with its own model, its own loop, and its own fresh context window, and it hands back only the result.
Nothing new enters the protocol. In the message array it is the exact tool_use / tool_result pair from Part 1; the tool simply happens to be a whole agent. The subagent runs an entire conversation the caller never sees, and only the final answer rides back.
Why one agent isn't enough
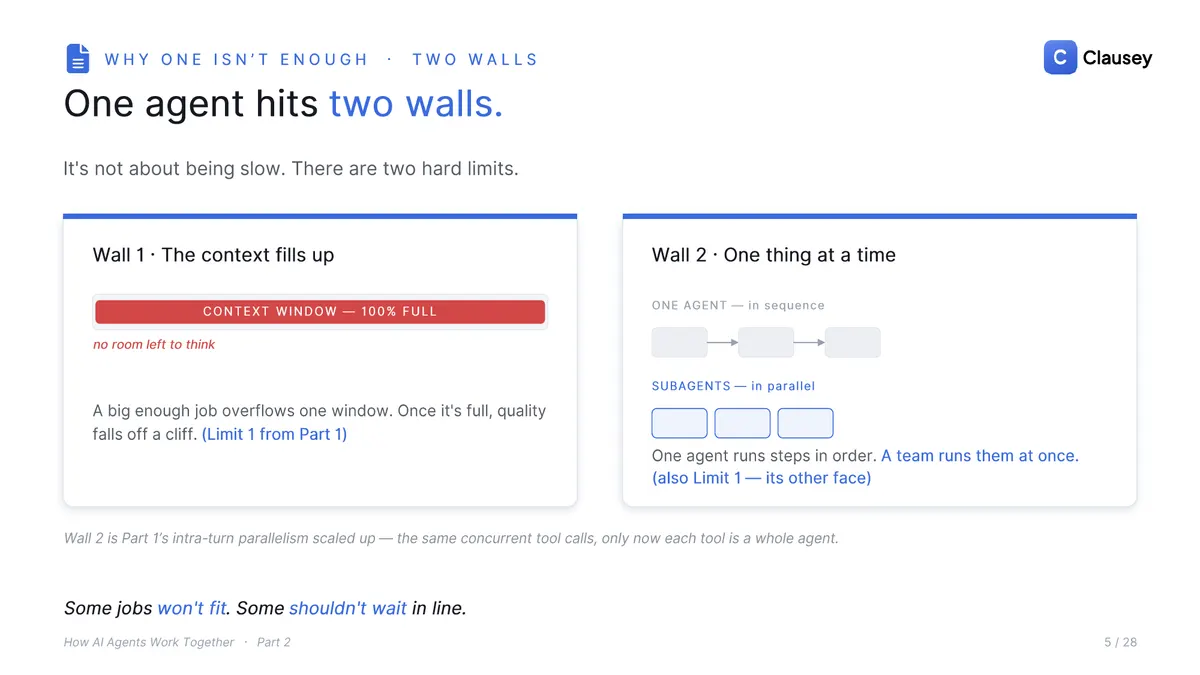
A single agent hits two walls. First, its context window fills up: a big enough job overflows the window, and once it is full, quality falls off a cliff. Second, it works in sequence, one thing at a time, while a team can run several at once. That second wall is really Part 1's parallel tool calls scaled up, except each "tool" is now a whole agent.
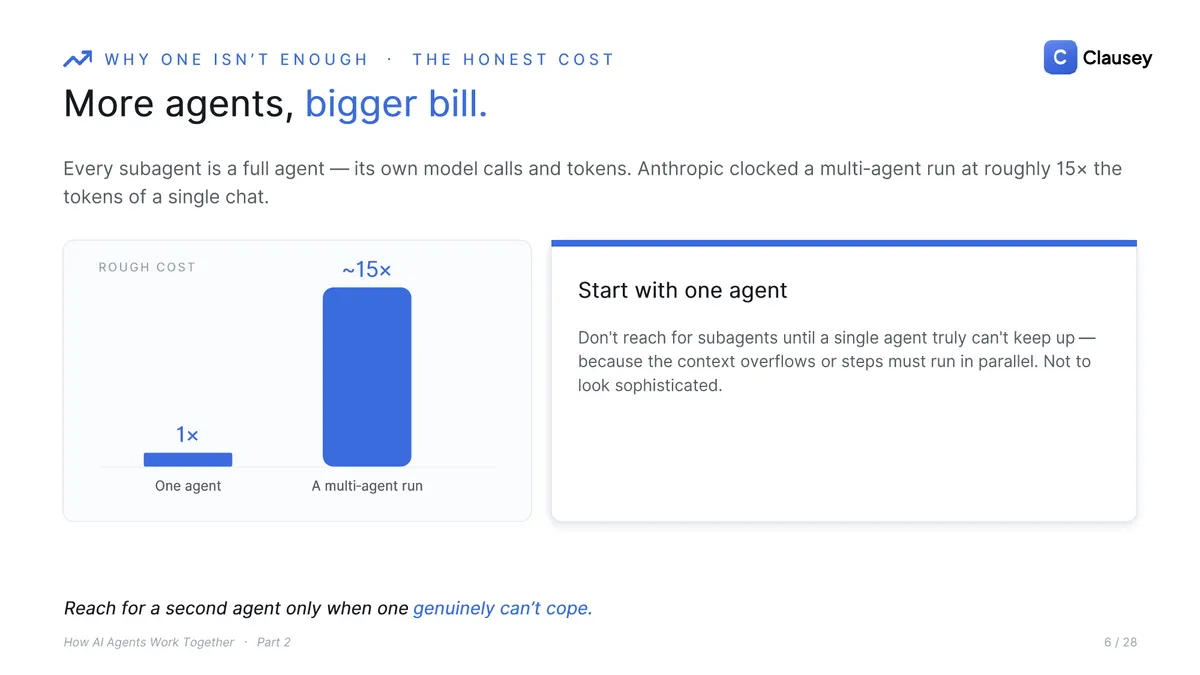
A team is not free, either. Every subagent is a full agent with its own model calls and tokens, so the bill climbs fast: Anthropic measured a multi-agent run at roughly 15x the tokens of a single chat. The rule that follows is to start with one agent. Reach for subagents only when one genuinely cannot cope, because the context overflows or steps truly must run in parallel, never just to look sophisticated.
The orchestrator does the coordinating
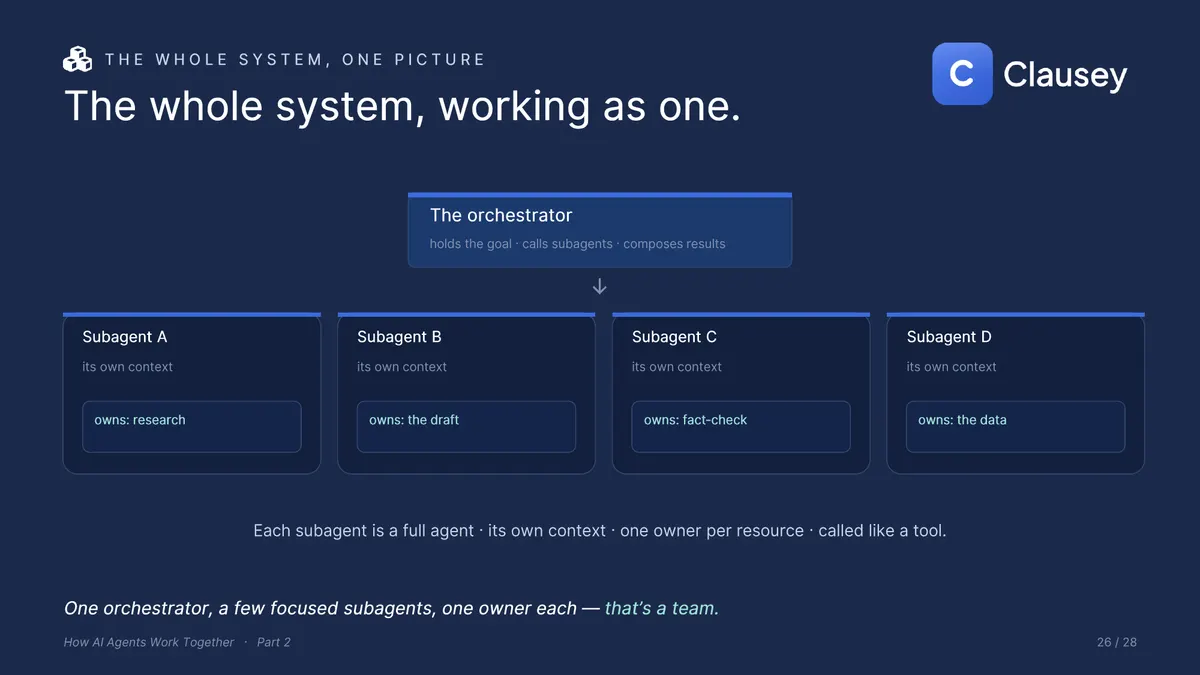
When you do split the work, one agent holds the overall goal, hands each subagent a smaller goal, calls them as tools, and stitches the results back together. That coordinator is the orchestrator, and it is not a special kind of software. It is the same machine from Part 1, given the job of coordinating.
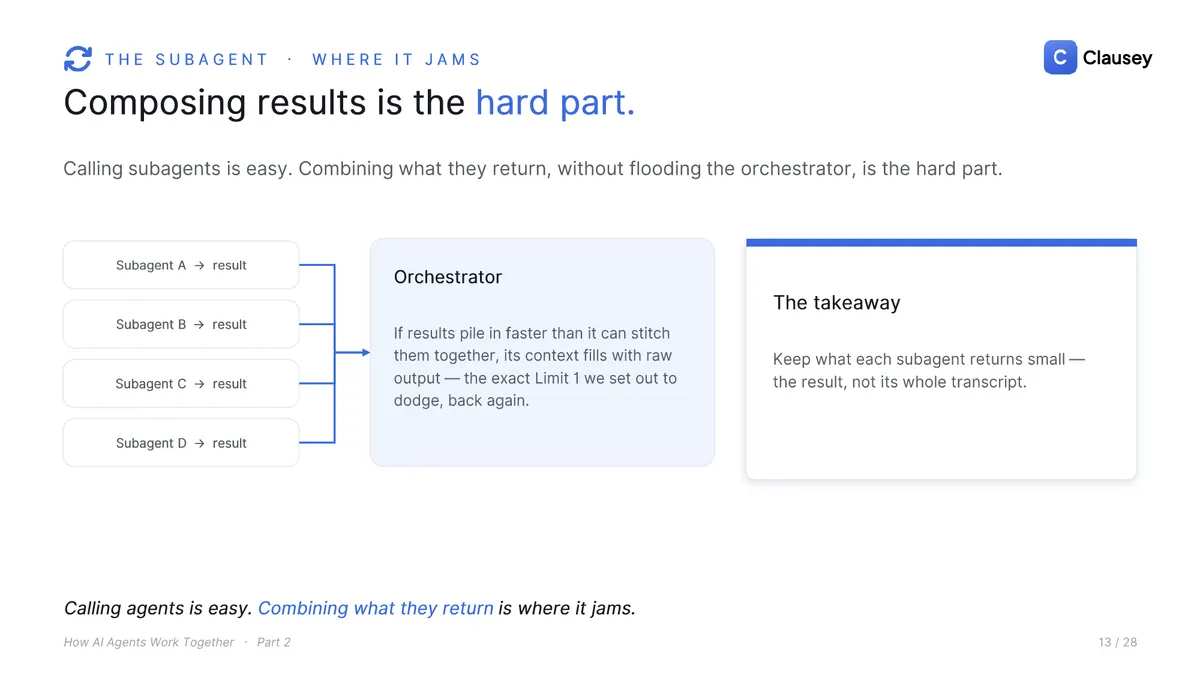
The payoff is context. A subagent does the heavy reading in its own window and returns a paragraph; the orchestrator's context stays small, like asking a colleague a question and getting back one clean answer instead of the fifty pages they read. The honest flip side: the orchestrator never sees those fifty pages, so it cannot course-correct mid-task, and if the answer is wrong the reasoning is already gone, which makes debugging harder.
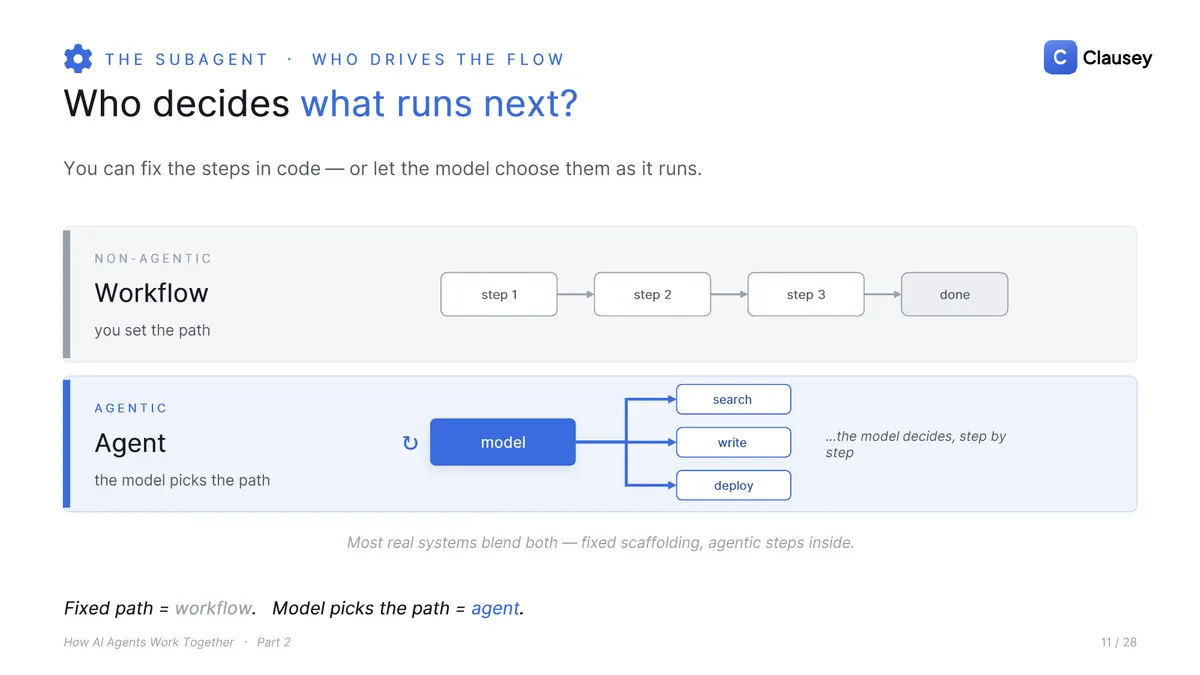
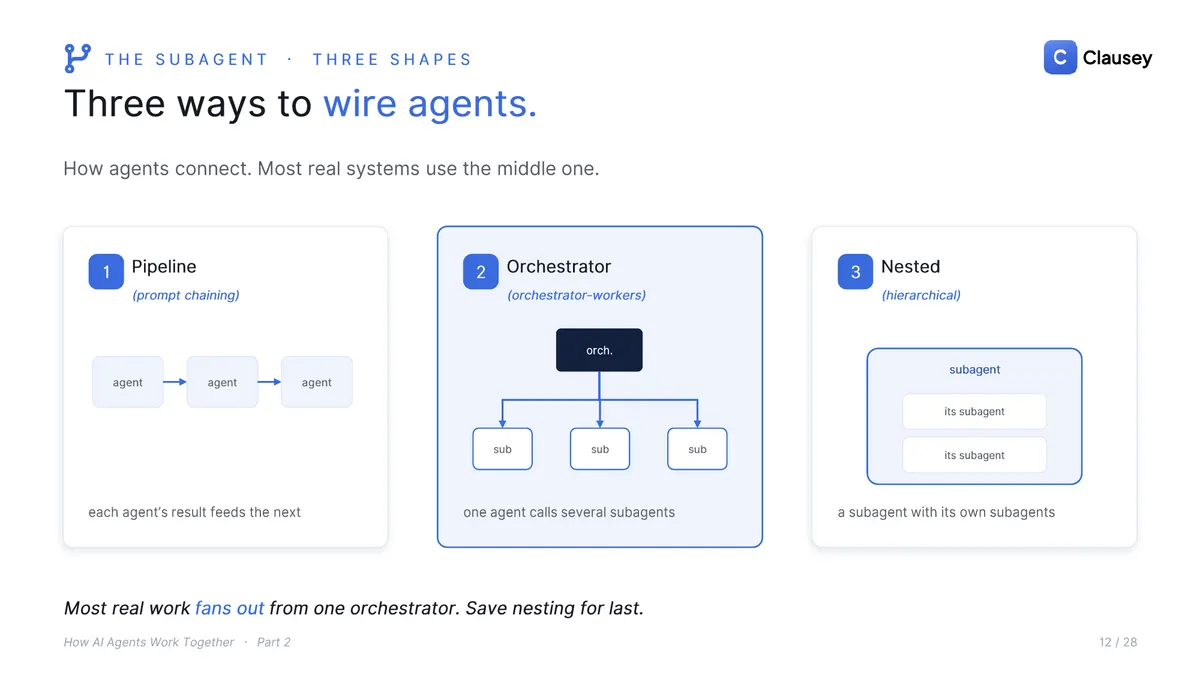
You can wire a team a few ways: a pipeline where each agent feeds the next, an orchestrator fanning out to several subagents, or subagents nested inside subagents. Most real work fans out from one orchestrator, so save nesting for last. And you can fix the path in code (a workflow) or let the model choose it as it goes (an agent); most real systems blend both.
Splitting the work cleanly
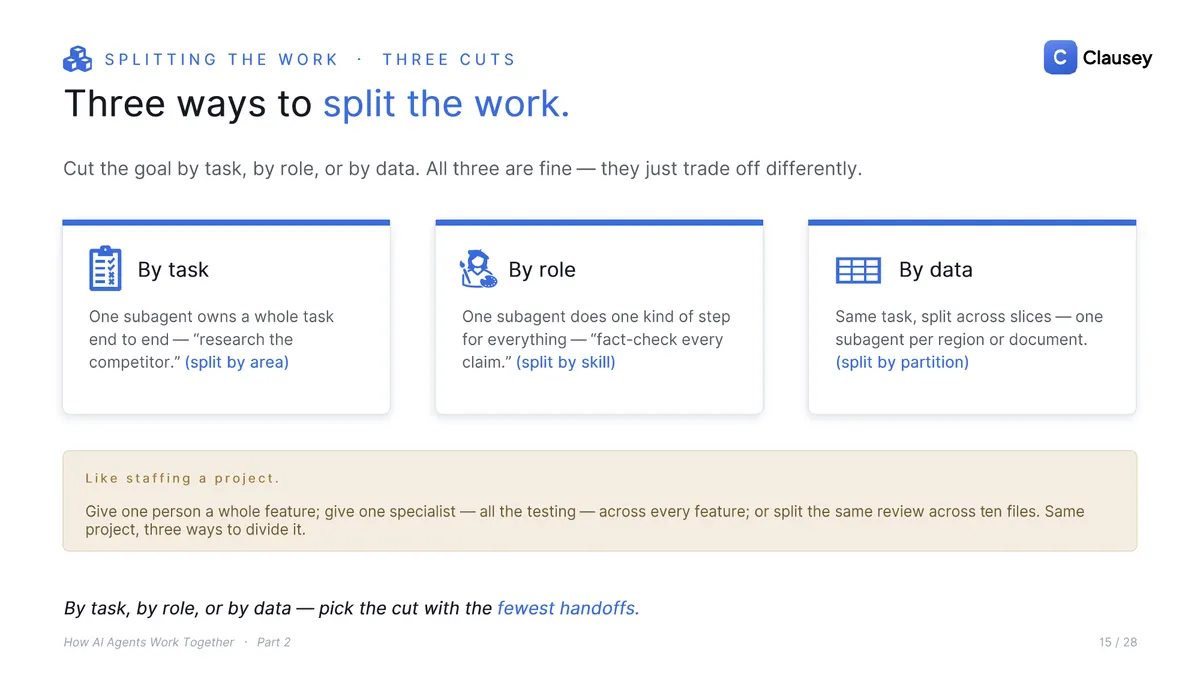
There are three honest ways to cut a goal. By task: one subagent owns a whole job end to end ("research the competitor"). By role: one subagent does a single kind of step for everything ("fact-check every claim"). By data: the same task split across slices, one subagent per region or document. None is wrong; pick the cut with the fewest handoffs.
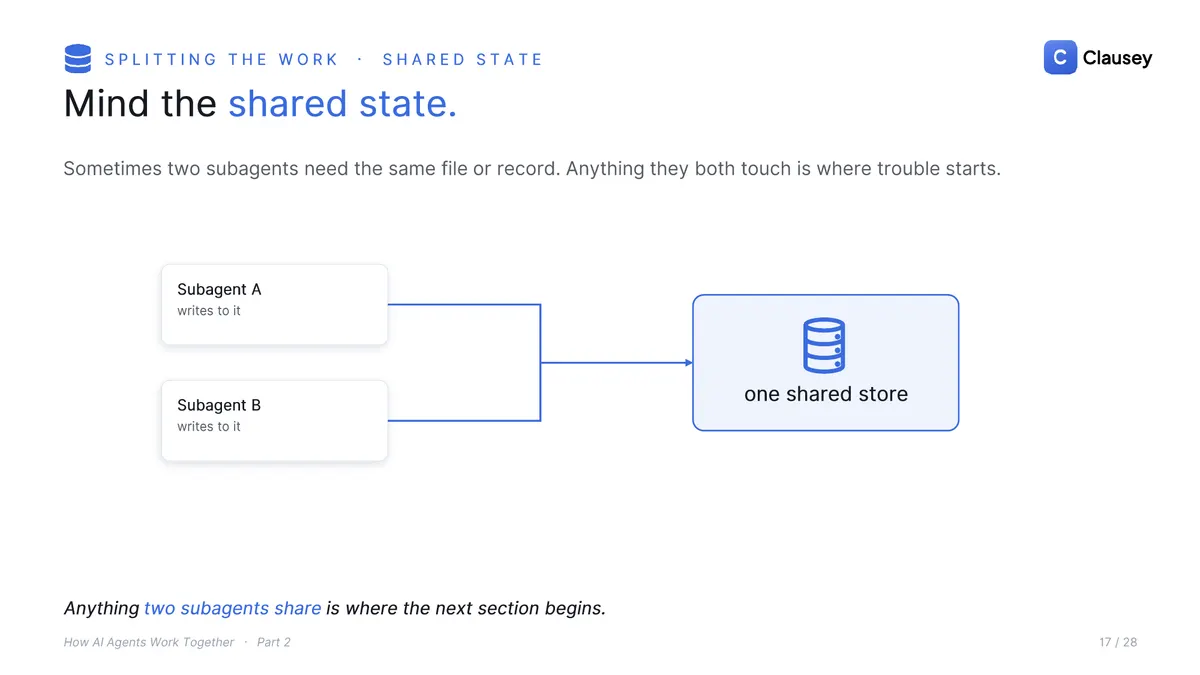
The principle underneath is clean boundaries: hand a subagent a whole task with a clear input and a clear output, not half a job that another agent has to finish. The fewer the handoffs, the less slips through the cracks. The place it goes wrong is shared state, anything two subagents both touch.
Keeping a team reliable
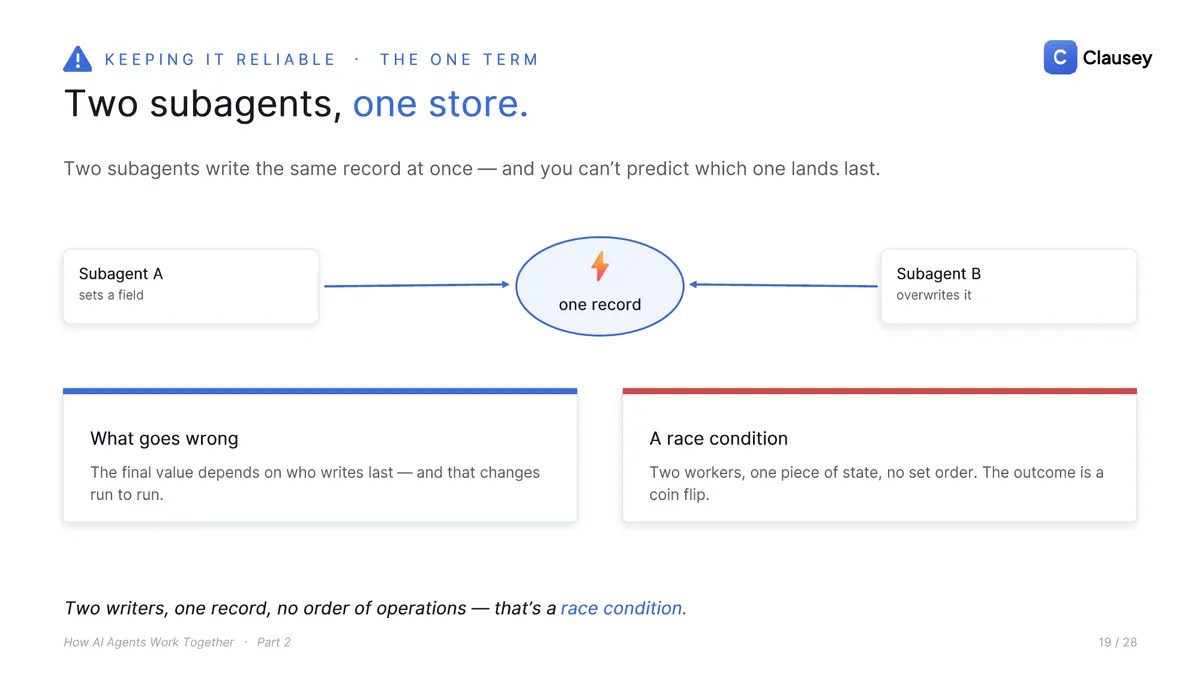
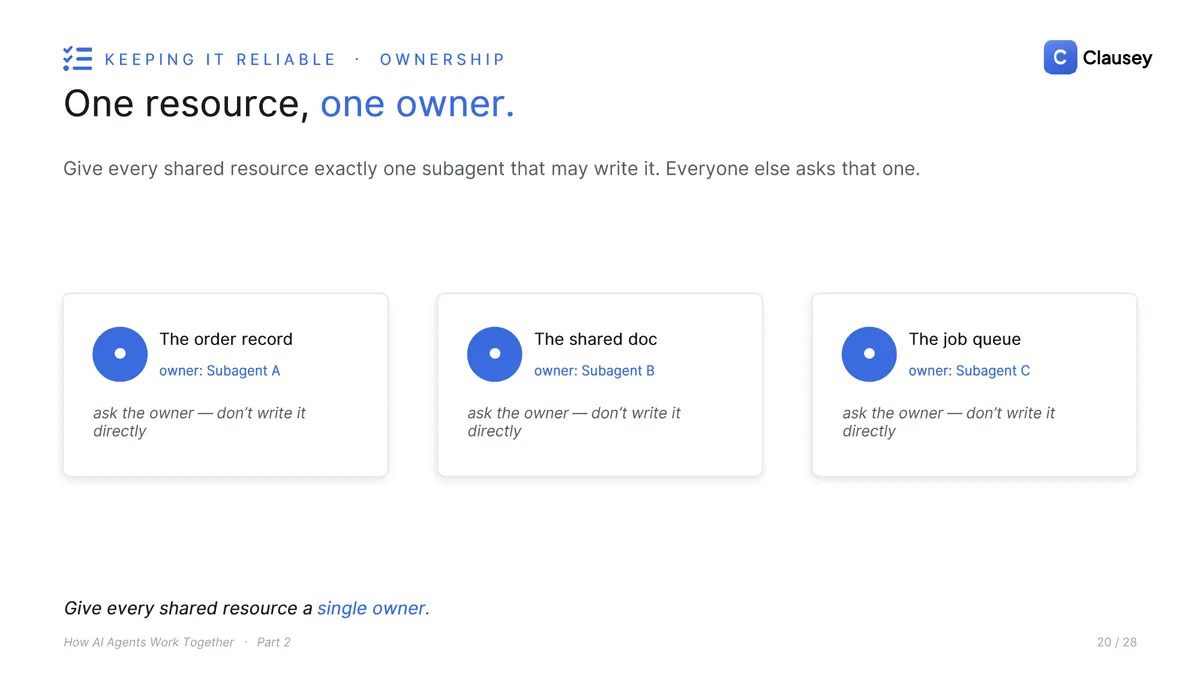
Run agents in parallel and a new class of bug shows up. If two subagents write the same record at once, you cannot predict which write lands last, so the result changes from one run to the next. That is a race condition, and the structural fix is ownership: give every shared resource exactly one subagent allowed to write it, and everyone else asks that owner.
Four more habits keep a team honest:
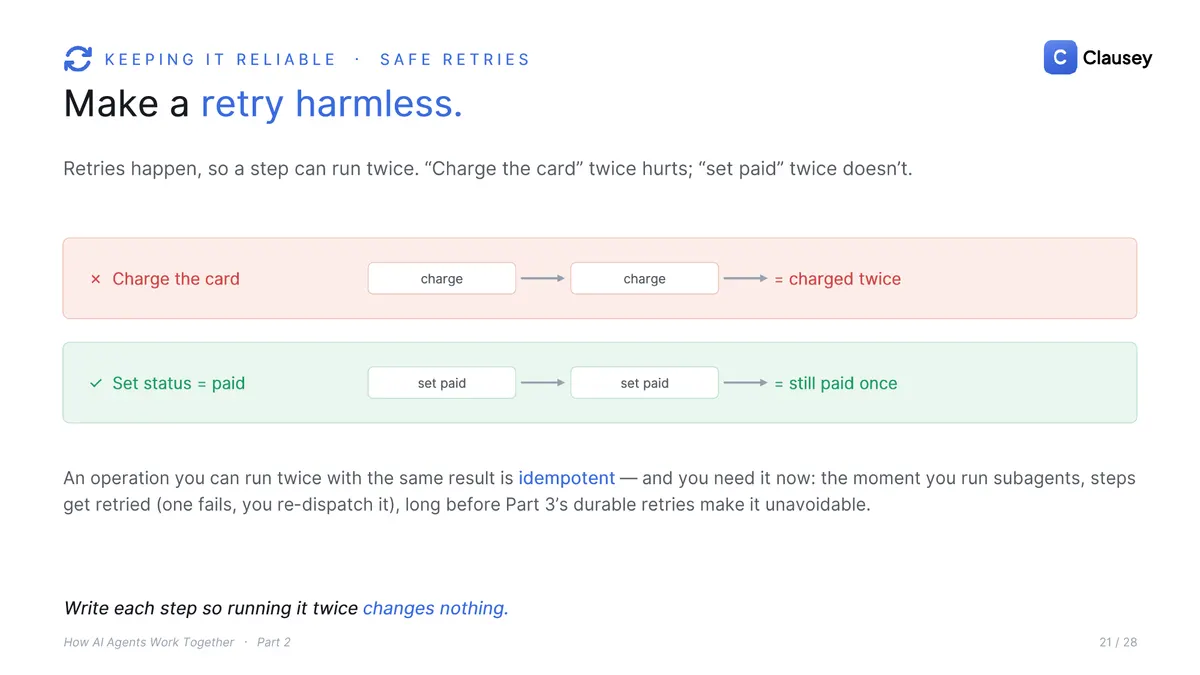
- Make retries harmless. The moment you run subagents, steps get retried; one fails, you re-dispatch it. "Charge the card" twice hurts; "set status to paid" twice does not. Write each step so running it twice changes nothing. The word for that is idempotent.
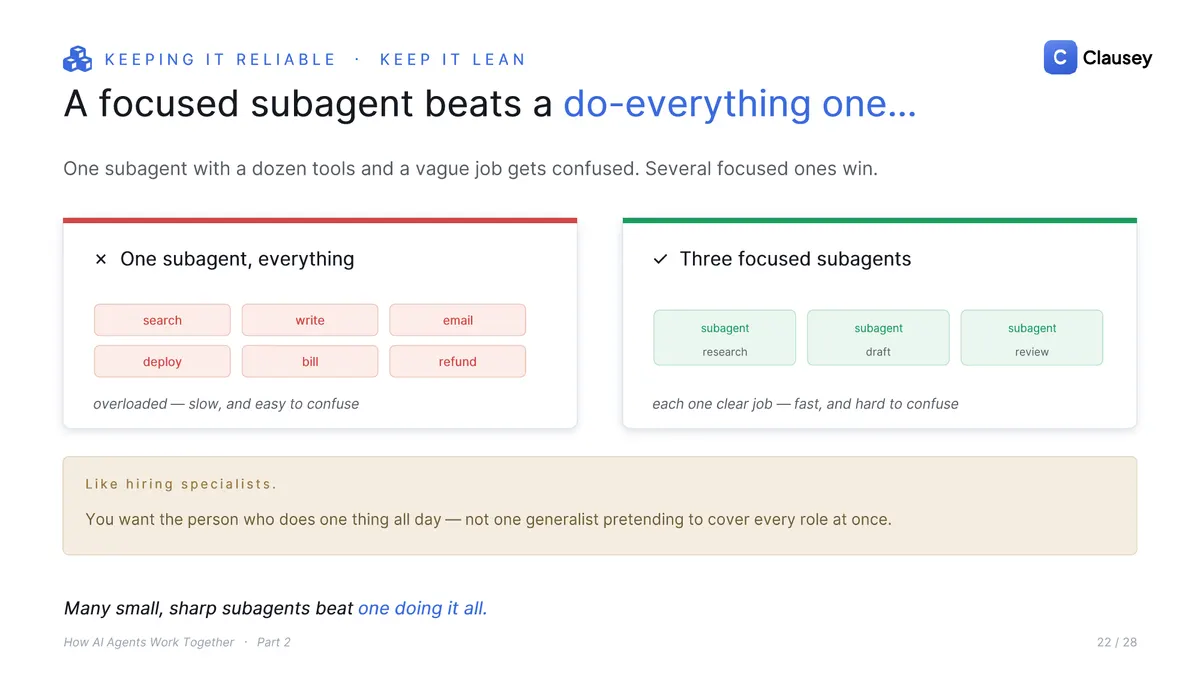
- Keep each subagent lean. One subagent with a dozen tools and a vague job gets confused; several focused ones do not. Hire specialists, not a generalist pretending to cover every role at once.
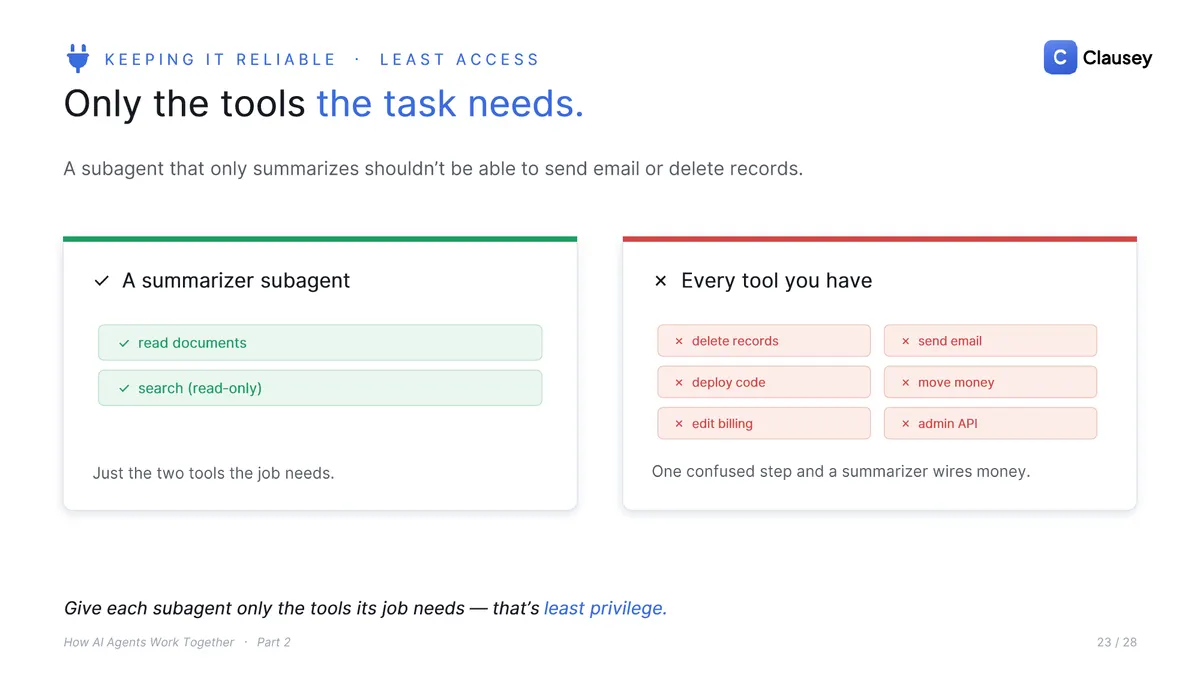
- Grant least privilege. A subagent that only summarizes has no business sending email or deleting records. Give each one only the tools its task needs.
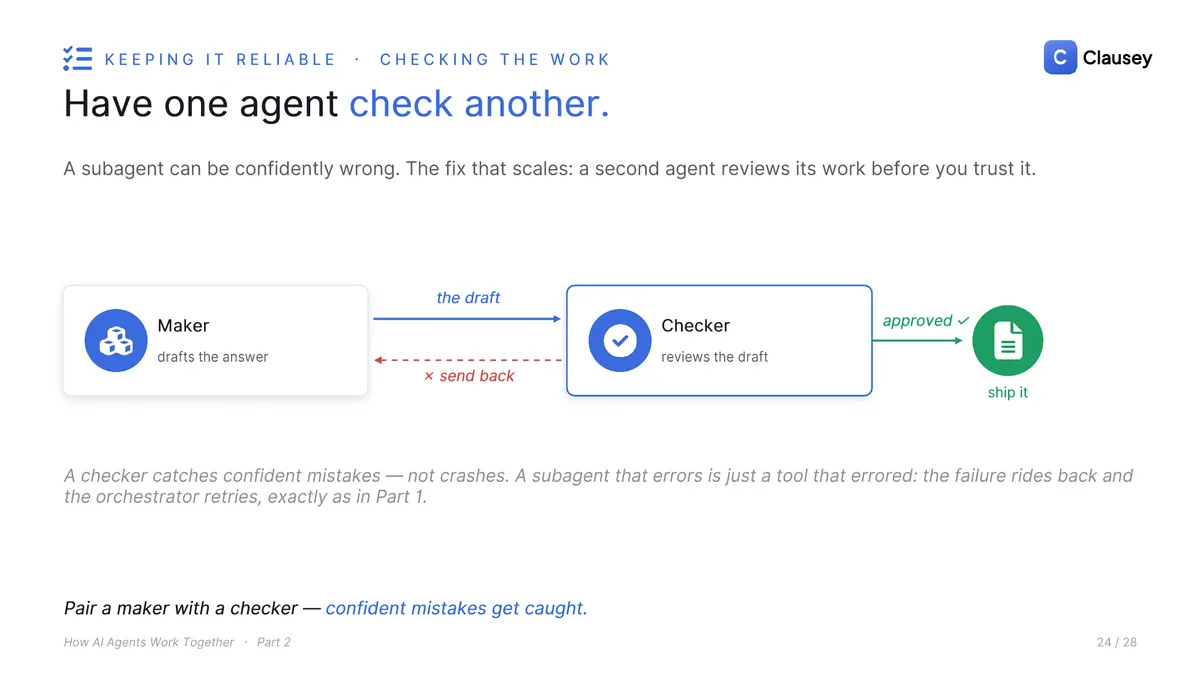
- Have one agent check another. A subagent can be confidently wrong, and confidence is not an error your code can catch. Pair a maker that drafts with a checker that reviews before you trust the output. A subagent that simply errors is easier: it is just a tool that errored, so the failure rides back and the orchestrator retries, exactly as in Part 1.
One job, start to finish
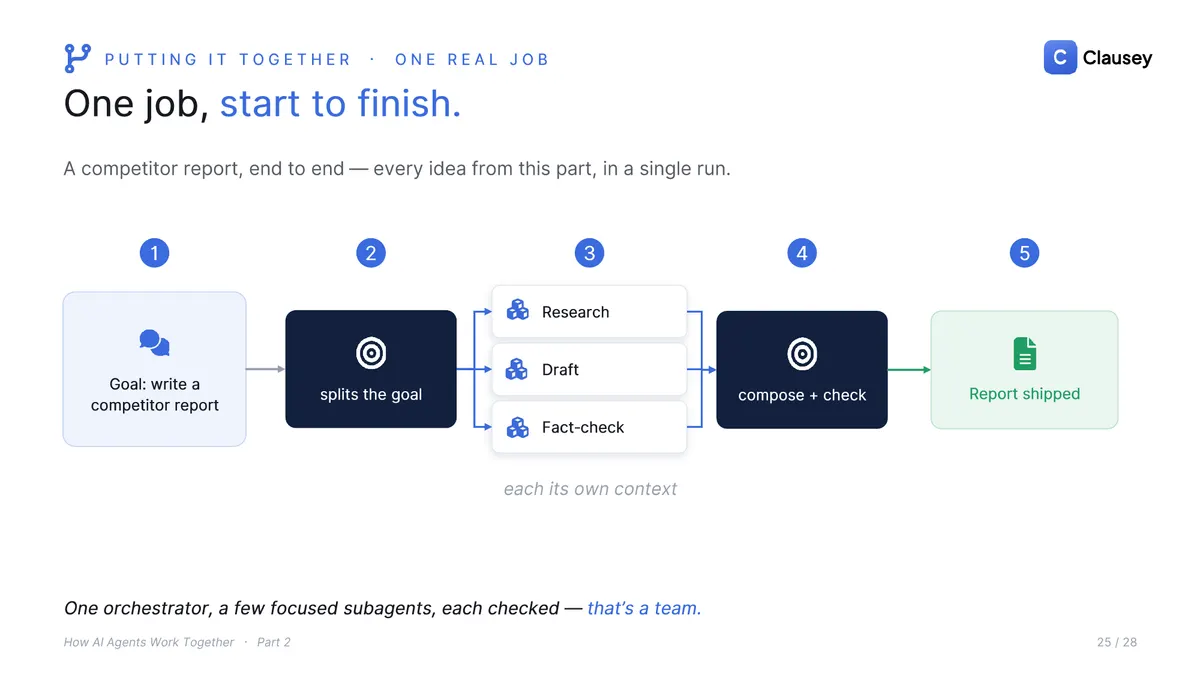
Put it together on something real, say a competitor report. The orchestrator splits the goal and fans out to focused subagents: one researches, one drafts, one fact-checks, each in its own context. Their answers come back, the orchestrator composes them, a checker reviews, and the report ships. One orchestrator, a few focused subagents, each owning its own resource, each checked: that is a team.
One wall down, one made worse
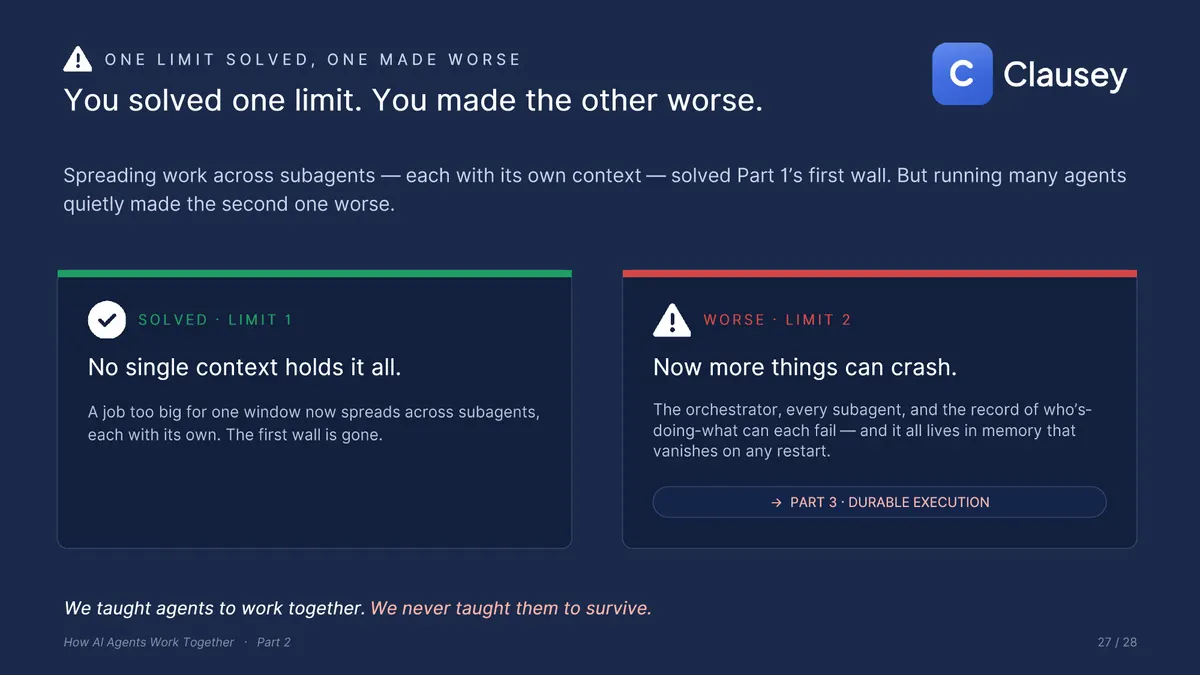
Spreading work across subagents solved Part 1's first wall: no single context has to hold the entire job anymore. But running many agents quietly made the second limit worse. The orchestrator, every subagent, and the running record of who is doing what can each fail, and all of it lives in memory that vanishes on any crash, timeout, or routine deploy. We taught the agents to work together; we never taught them to survive. That is the subject of Part 3.
Where Clausey fits
This is the architecture Clausey runs on. Ask a question across your documents and a master agent orchestrates focused subagents, each reading in its own context and returning just what it found, then composes them into one answer, grounded in your own files and cited back to the page. The same idea that turns a single agent into a team is what lets Clausey reason over a whole library at once instead of one page at a time.
So the next time a product says it "puts a team of AI agents on your data," you will know exactly what that means: an orchestrator, a few focused subagents, and one owner per shared resource.
Get the latest product news and behind the scenes updates.