Building Autonomous Agents for Regulated Workflows


Most AI agent demos can't survive an audit. They plan beautifully and execute impressively, right up until a regulator asks what the agent did six months ago, who authorized it, and whether you can prove it. For autonomous agents in regulated workflows — FP&A, SOX, model risk, MiFID II — that question is the whole game, and it has no model-level answer.
This is how we build agents that can answer it, in plain English and faithful to the deck below. The thesis is simple: planning is converging fast, but execution is where every enterprise pilot dies, and the fix is architectural, not aspirational. The deck is the whole argument; the written breakdown follows.





Most AI agent demos can't survive an audit
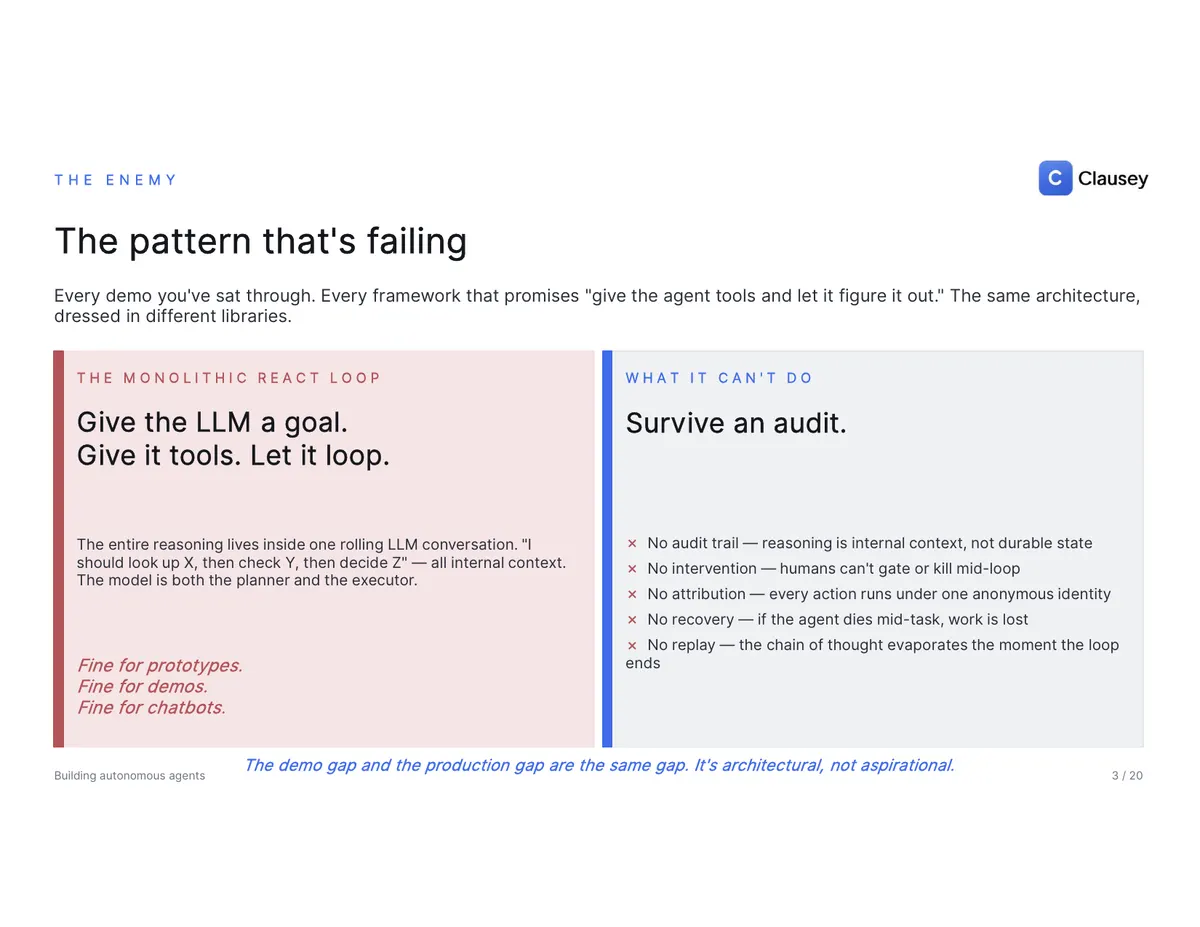
The pattern that's failing is the one every framework sells: give the LLM a goal, give it tools, let it loop. The entire reasoning lives inside one rolling conversation, and the model is both the planner and the executor. That's fine for prototypes, demos, and chatbots. It cannot survive an audit, because the architecture provides none of what an auditor needs: no audit trail (the reasoning is internal context, not durable state), no intervention (a human can't gate or kill the loop mid-flight), no attribution (every action runs under one anonymous identity), no recovery (if the agent dies mid-task, the work is lost), and no replay (the chain of thought evaporates the moment the loop ends). The demo gap and the production gap are the same gap.
Planning is solved. Execution is the bottleneck.
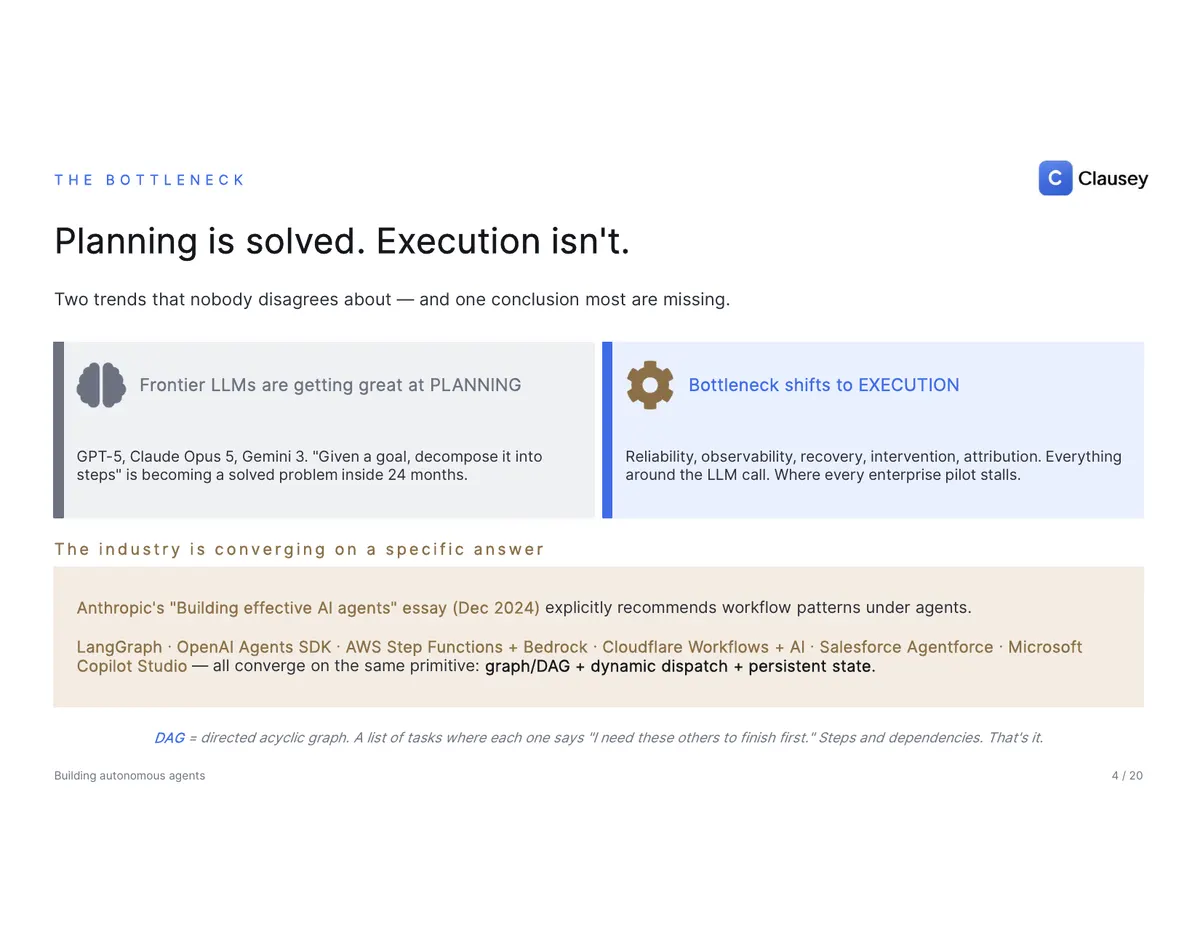
Two trends are no longer controversial. Frontier models are getting genuinely good at planning — "given a goal, decompose it into steps" is becoming a solved problem. And as it does, the bottleneck moves to everything around the LLM call: reliability, observability, recovery, intervention, and attribution. That's where pilots stall. The industry has quietly converged on the same answer — Anthropic's "Building effective AI agents" guidance, LangGraph, the OpenAI Agents SDK, AWS Step Functions, Cloudflare Workflows, Salesforce, and Microsoft all land on the same primitive: a graph of steps (a DAG), dynamic dispatch, and persistent state. A DAG is just a task list where each item declares what has to finish before it can run. The interesting work isn't teaching the model to plan; it's running that plan in a way you can prove.
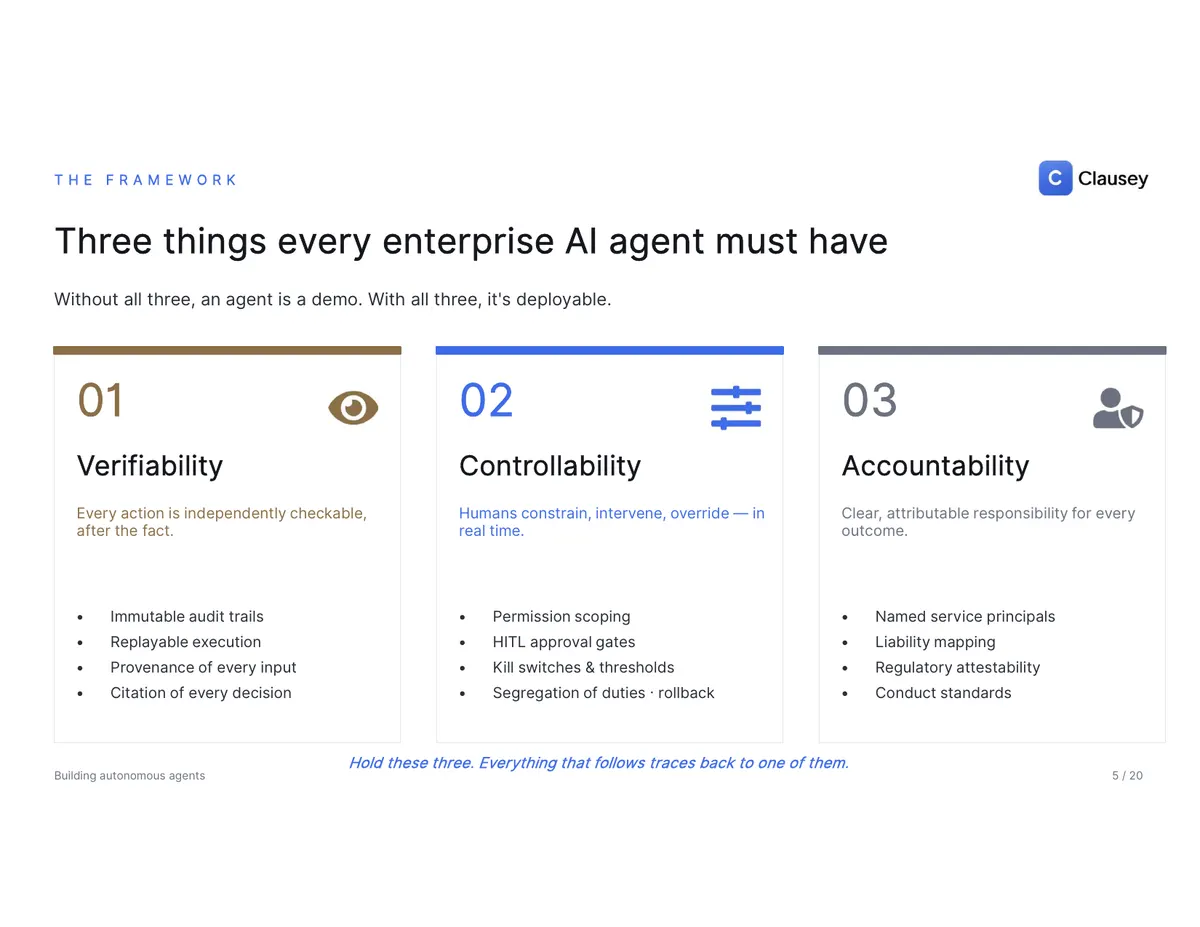
Three things every enterprise agent must have
Without all three of these, an agent is a demo. With all three, it's deployable.
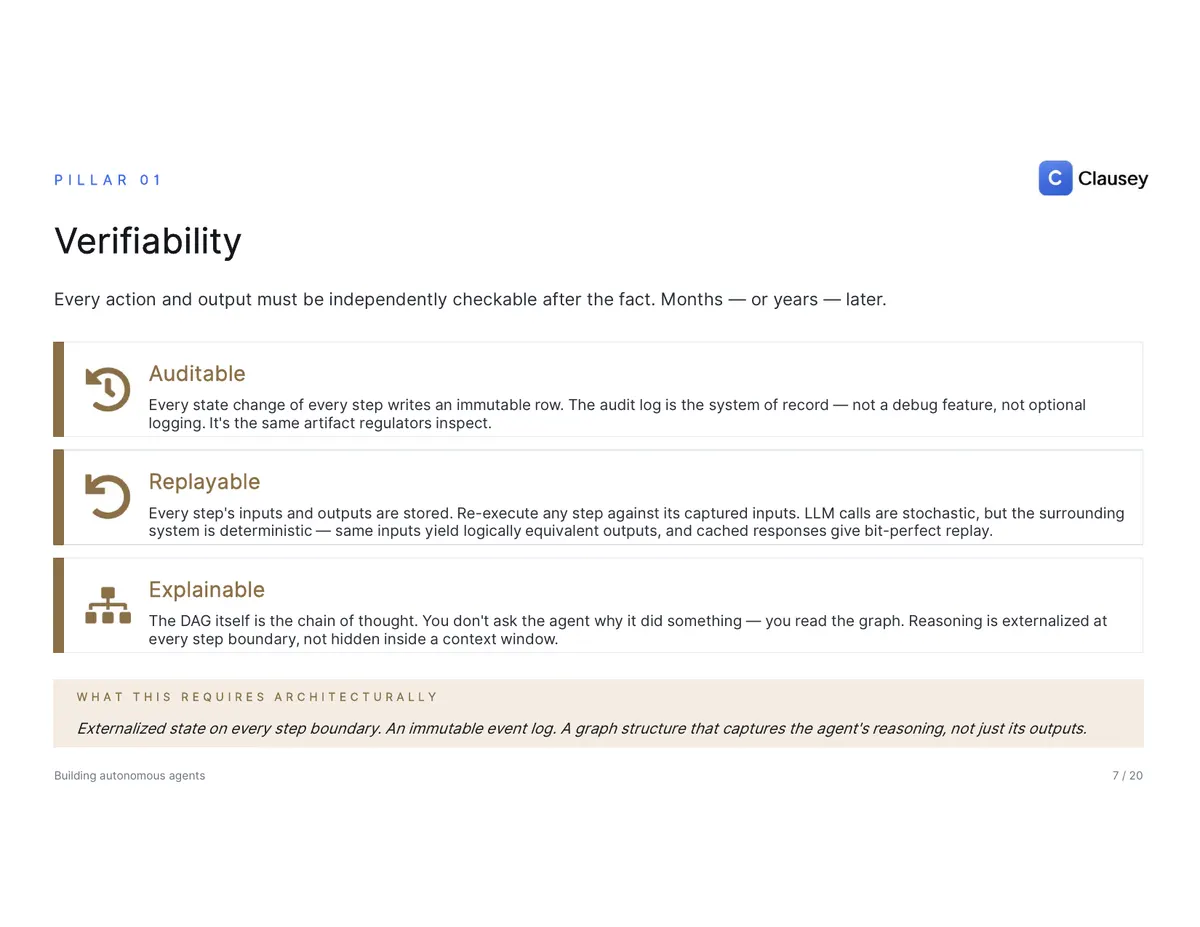
- Verifiability — every action is independently checkable after the fact: an immutable audit trail, replayable execution, the provenance of every input, and a citation for every decision.
- Controllability — humans can constrain, intervene, and override in real time: permission scoping, human-in-the-loop approval gates, kill switches, per-skill thresholds, segregation of duties, and rollback.
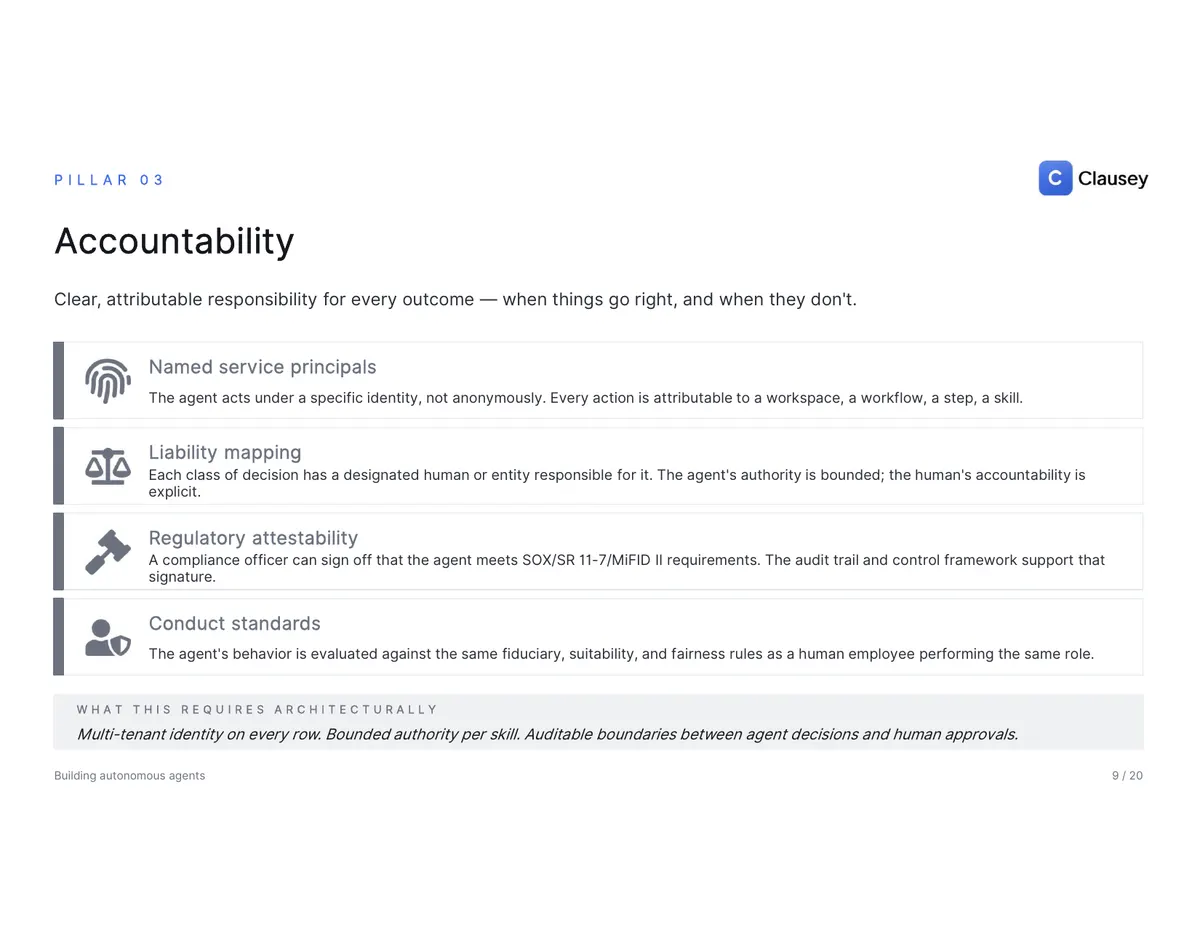
- Accountability — clear, attributable responsibility for every outcome: a named principal behind every action, a liability map from each class of decision to a responsible human, and conduct standards held to the same bar as an employee in the same role.
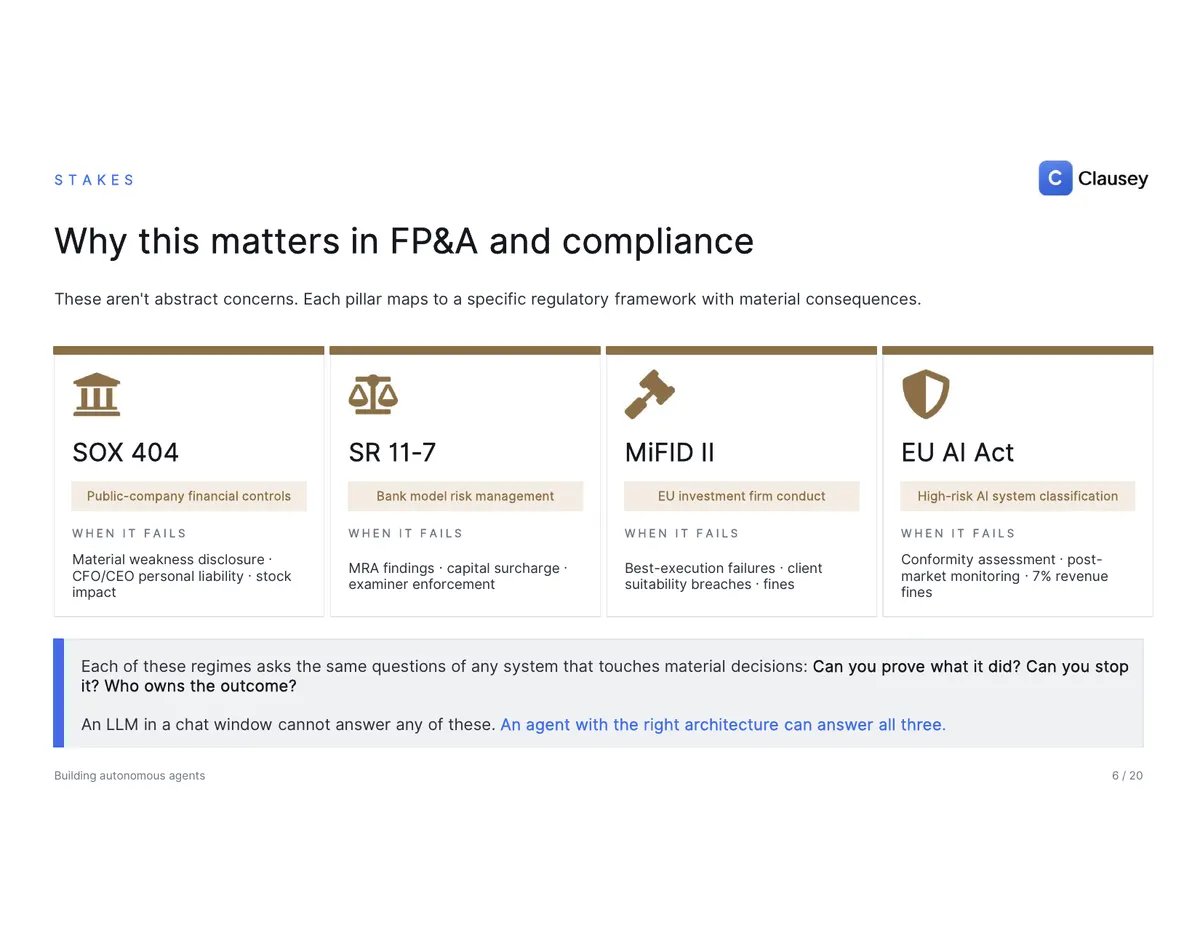
These aren't abstract. In FP&A and compliance they map straight onto regulation: SOX 404, where failure means a material-weakness disclosure and personal liability for the CFO; SR 11-7 for bank model risk; MiFID II for investment-firm conduct; and the EU AI Act, which can fine high-risk systems up to 7% of global revenue. Every one of those regimes asks the same three questions: can you prove what it did, can you stop it, and who owns the outcome. An LLM in a chat window can't answer any of them. An agent with the right architecture answers all three.
Two architectural properties make all three possible
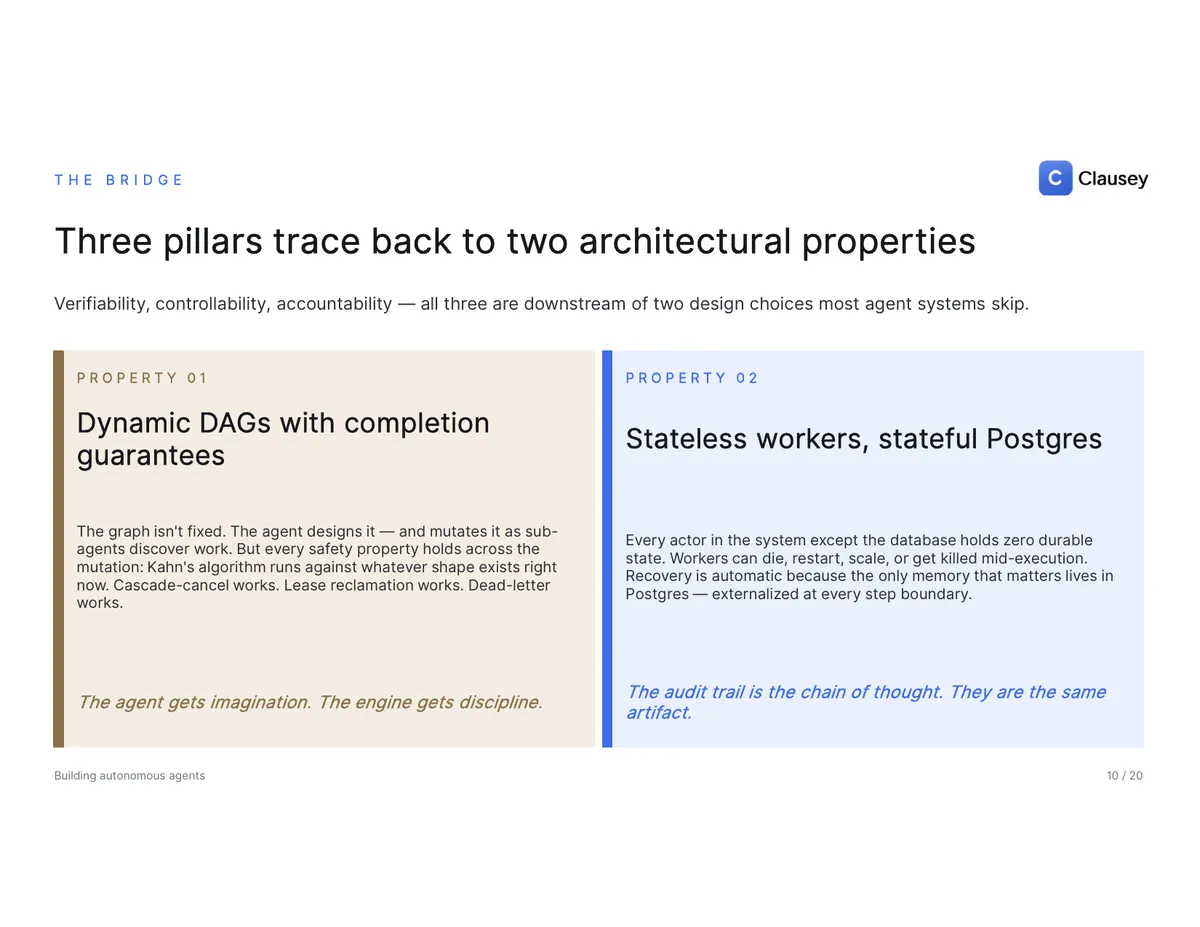
The three pillars trace back to two design choices most agent systems skip.
The first is dynamic DAGs with completion guarantees. The graph isn't fixed — the agent designs it, and mutates it as sub-agents discover new work. But every safety property holds across that mutation: the scheduler (Kahn's topological sort) runs against whatever shape exists right now, cascading cancellation reaches the new nodes, expired leases reclaim them, and the dead-letter path catches the ones that fail for good. The agent gets imagination; the engine gets discipline.
The second is stateless workers over a stateful database. Every actor in the system except the database holds zero durable state. Workers can die, restart, scale, or be killed mid-execution, and recovery is automatic, because the only memory that matters lives in Postgres, externalized at every step boundary. No Redis, no Kafka, no Temporal: the database is the source of truth and hands out atomic job claims for free — a deliberately boring stack.
Three actors, one source of truth
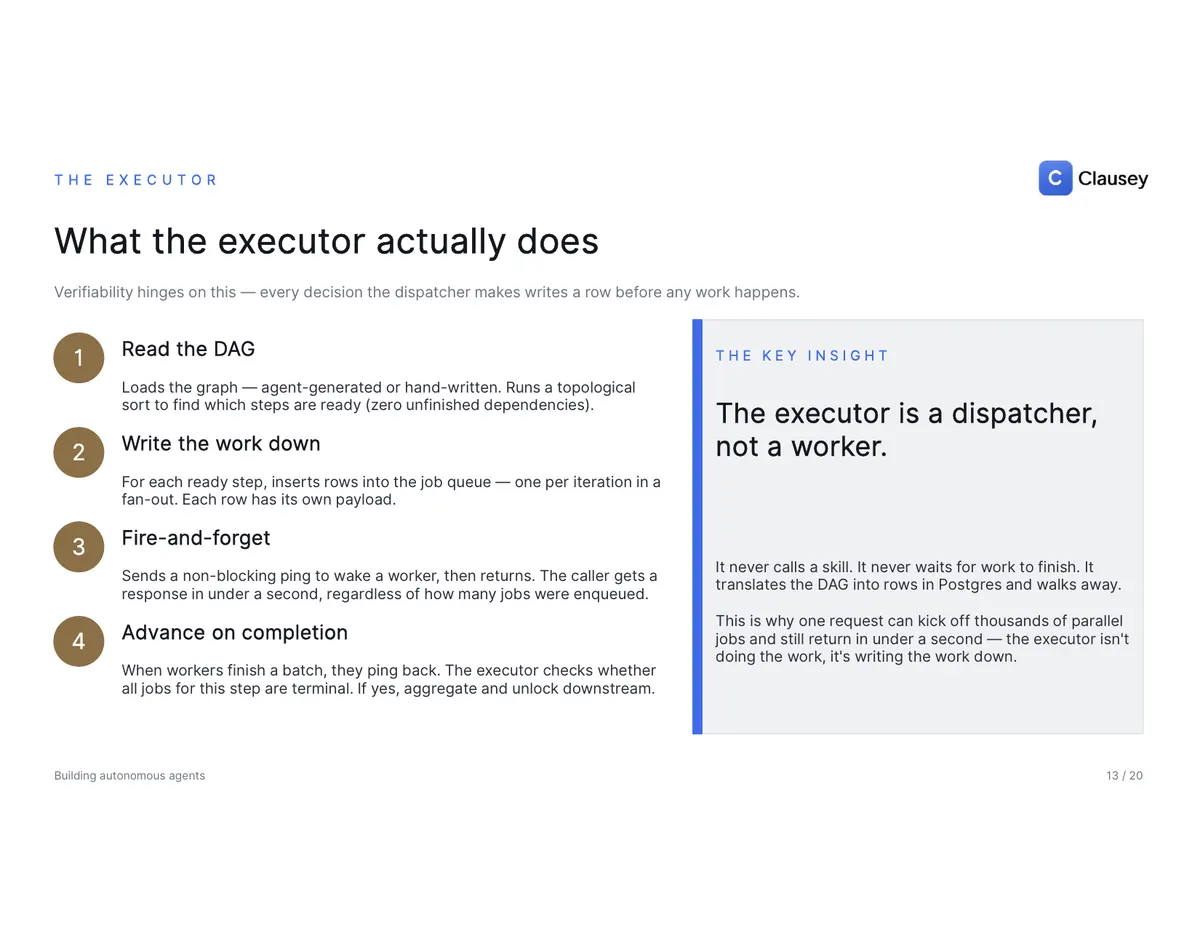
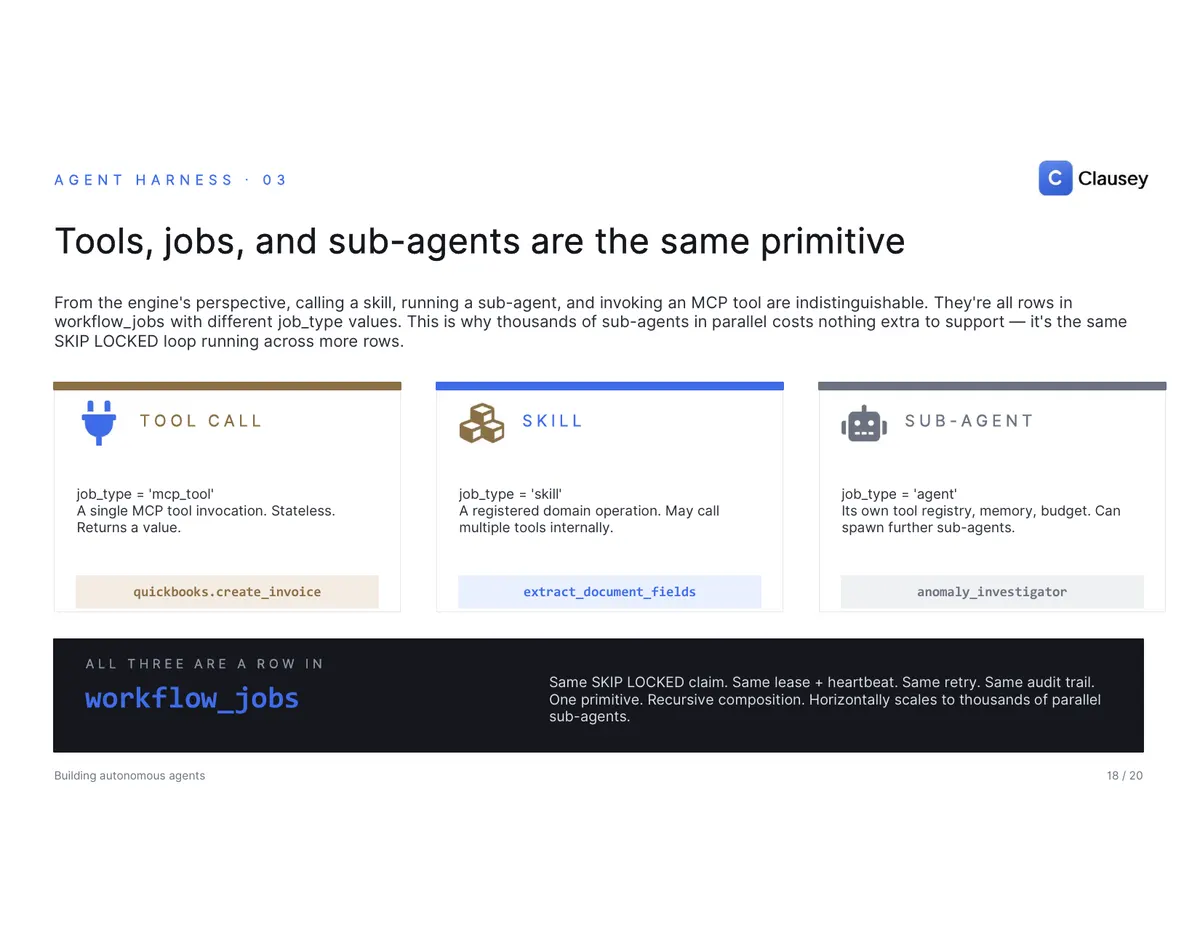
The engine is three things talking to each other, and only one of them remembers anything. A dispatcher reads the DAG, runs the topological sort to find which steps are ready, and writes the work down as rows in a job queue — then returns in under a second, no matter how many jobs it just enqueued. It never calls a skill itself; it's a dispatcher, not a worker. A pool of stateless workers claims those jobs atomically (Postgres SKIP LOCKED guarantees no two workers grab the same one), runs the work, heartbeats to hold a lease that auto-recovers if the worker dies, and reports the outcome. And Postgres holds every row of state, provides the atomic claims, runs cron-based safety nets, and survives any worker crash.
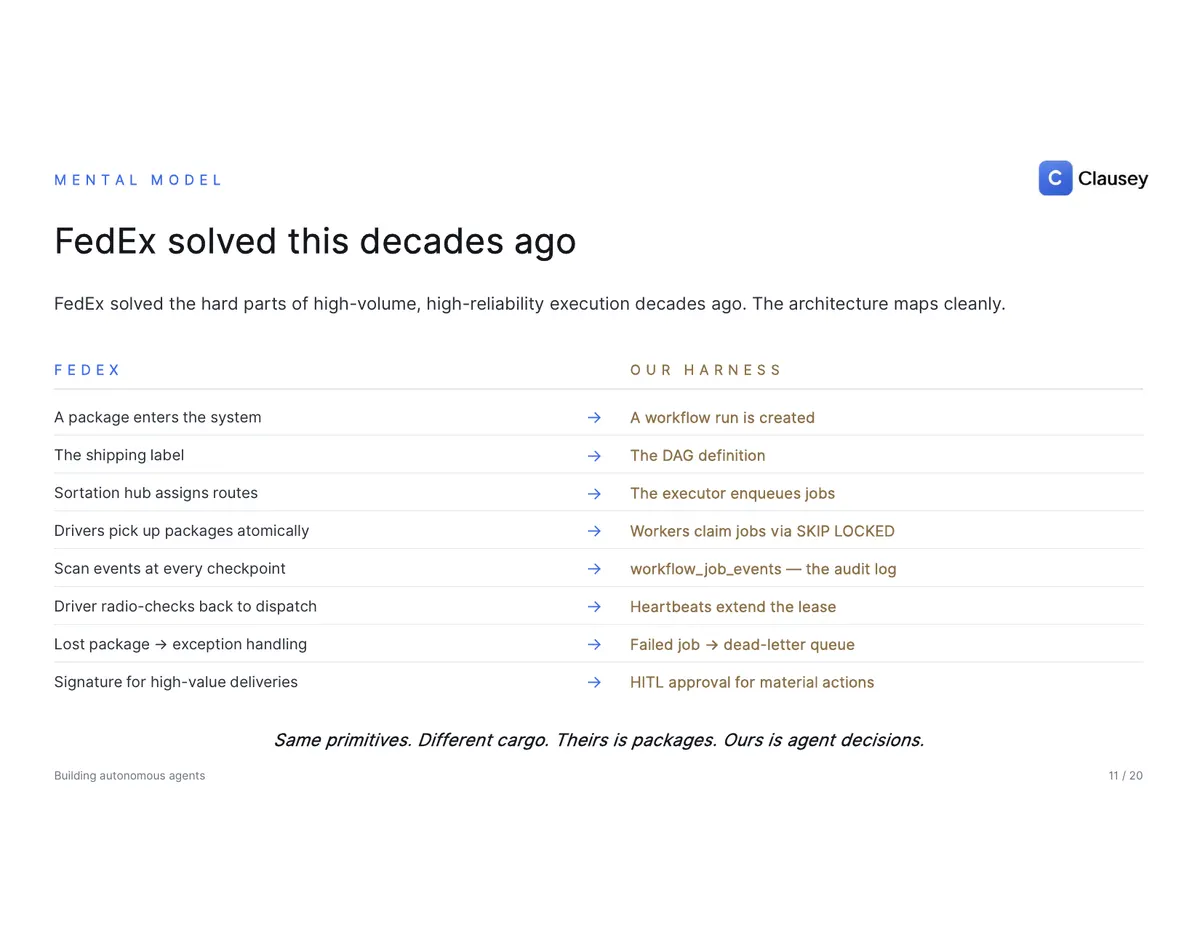
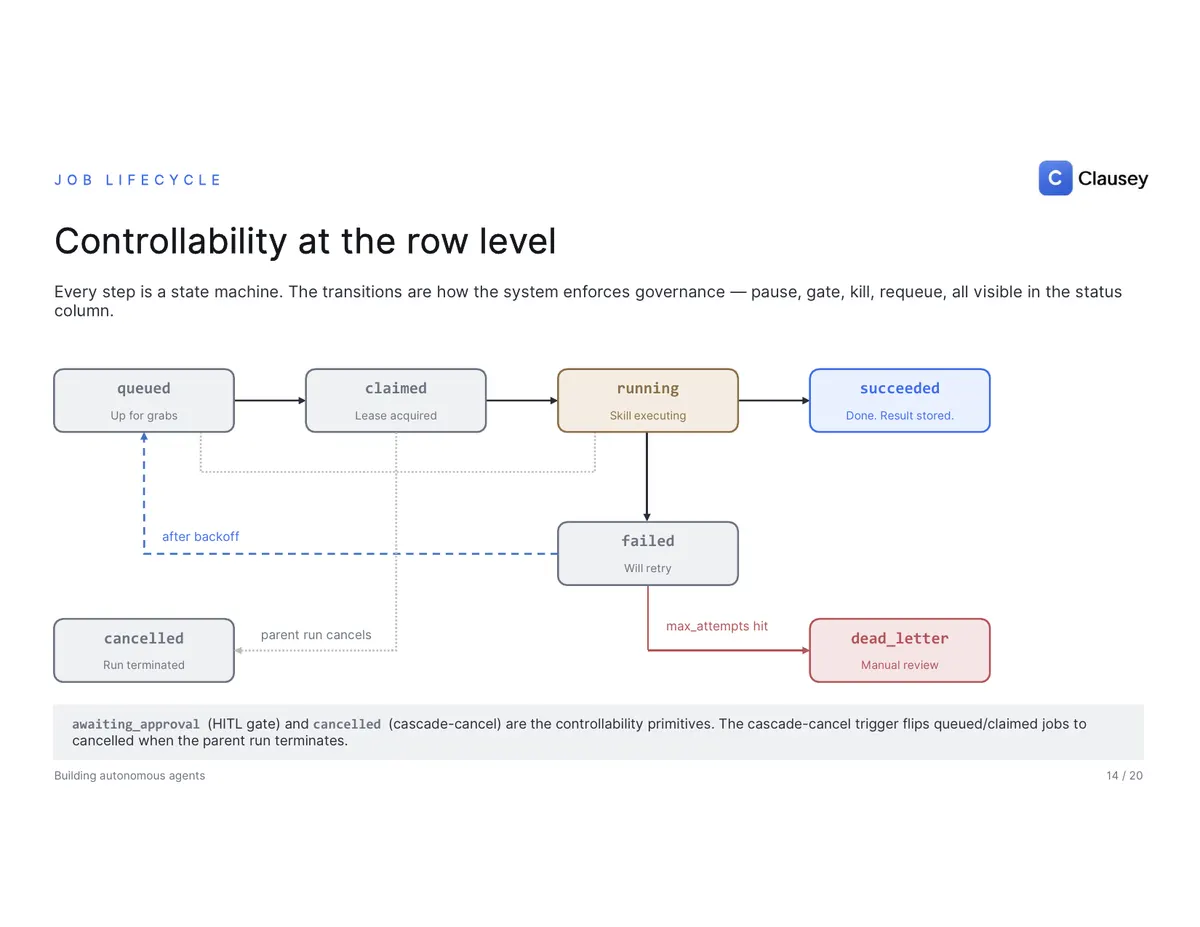
FedEx solved this shape decades ago: a package enters the system (a run is created), the label defines the route (the DAG), the sortation hub assigns work (the dispatcher enqueues jobs), drivers pick up packages atomically (workers claim jobs), every checkpoint is scanned (the event log), and high-value deliveries need a signature (a human approval gate). Same primitives, different cargo — theirs is packages, ours is agent decisions. And because every step is a row with a state machine — queued, claimed, running, succeeded, then either failed-and-retried with backoff or dead-lettered for manual review — controllability is just a column: an approval gate parks a run indefinitely without losing state, and a single cascade-cancel flips every in-flight job to cancelled with no orphans.
The agent writes the graph; the engine runs it
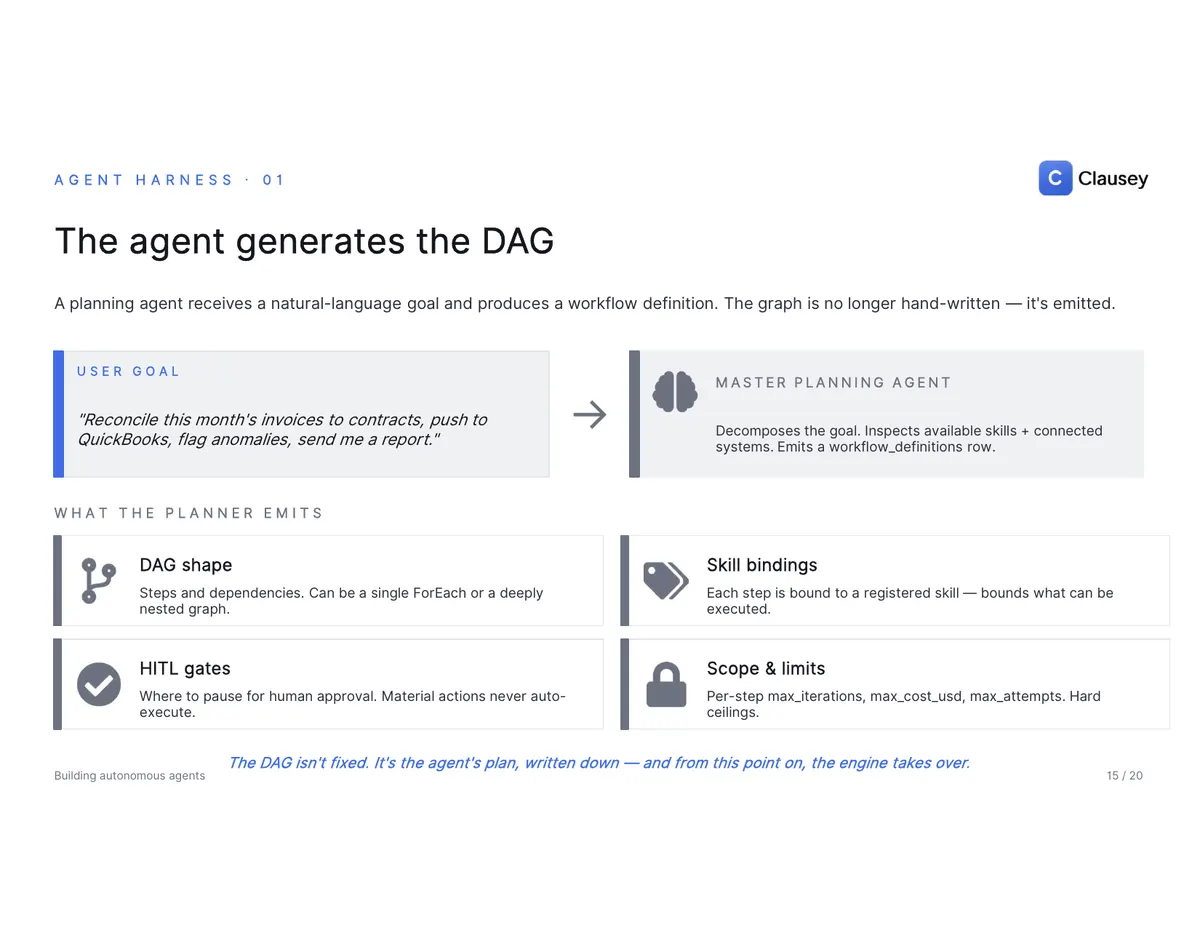
Here's where it comes together. A planning agent takes a natural-language goal — "reconcile this month's invoices to contracts, push to QuickBooks, flag anomalies, send me a report" — inspects the available skills and connected systems, and emits a workflow definition: the DAG shape, the skill bound to each step, the gates where a human must approve, and hard per-step ceilings on iterations, cost, and retries. The plan is written down, and from there the engine takes over.
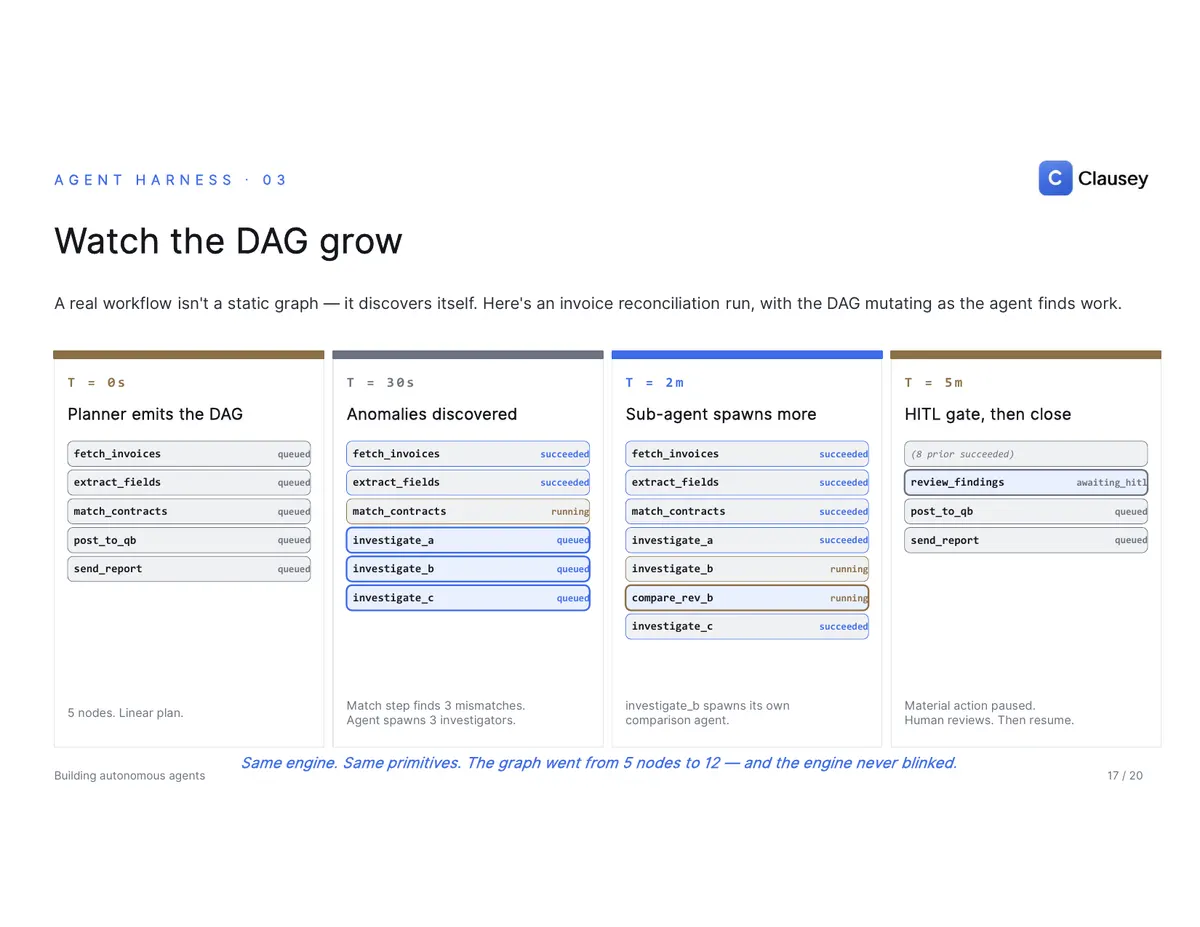
Crucially, the DAG isn't frozen. Agents discover work as they run, inserting new steps at runtime, and the engine doesn't care that they weren't there ten seconds ago — the same primitives that handle a static five-node graph handle a five-thousand-node one that materialized mid-run. In a real reconciliation run, the plan starts at five linear steps; the match step finds three mismatches, the agent spawns three investigators, one of those spawns its own comparison agent, a human approves the findings at a gate, and the run closes. The graph grew from five nodes to twelve, and the engine never blinked.
And from the engine's point of view, a tool call, a skill, and a sub-agent are the same primitive: all of them are rows in the same queue with a different type, claimed the same way, leased the same way, retried the same way, and written to the same audit trail. That's what lets a single run fan out into thousands of parallel sub-agents with no special-case code.
The audit trail is the chain of thought
Every governance property in this design traces back to one choice: workers hold no state, and the database holds all of it. A monolithic loop keeps its reasoning in volatile context — a black box between writes that you can't replay, can't interrupt, can't attribute, and can't recover. DAG-structured execution forces every reasoning step to cross the database at a step boundary: every input and output is captured (replayable), the run can be paused or cancelled between steps (interruptible), every row carries its workspace and the worker that claimed it (attributable), and any dead worker's lease simply expires and requeues (recoverable).
So the database is the audit trail, and the audit trail is the chain of thought — they are the same artifact. Stateless workers over a stateful database aren't a performance optimization; they are the precondition for governance. When an external auditor asks, in September, to replay a decision the agent made in March, the answer is a query, not a forensic investigation.
The thesis, and where Clausey fits
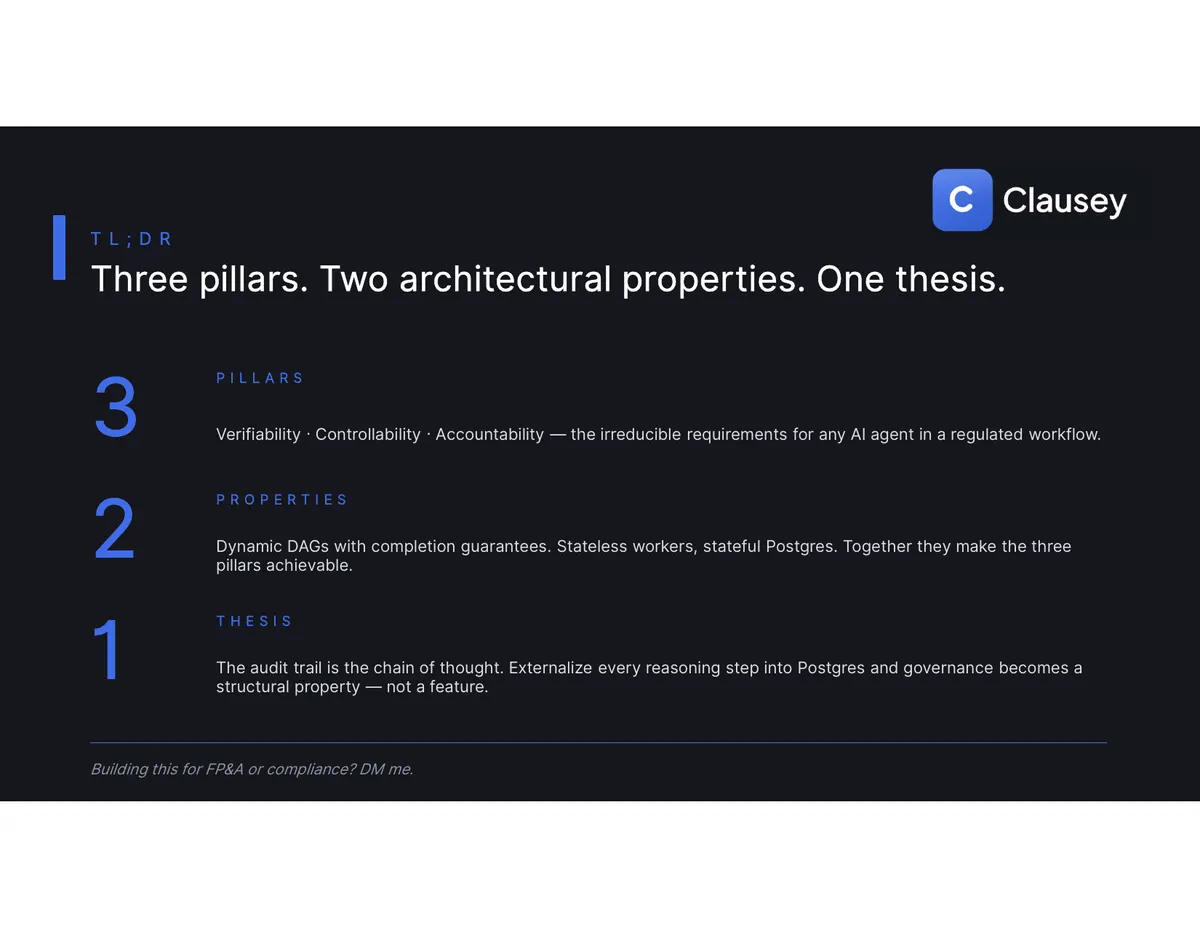
Three pillars — verifiability, controllability, accountability. Two architectural properties — dynamic DAGs with completion guarantees, and stateless workers over a stateful database. One thesis: externalize every reasoning step into the database, and governance stops being a feature you bolt on and becomes a structural property you can't avoid.
This is the engine Clausey is built on. We point it at your documents and your rulebook: it reads your files, structures them into data, checks them against your policies, and runs the work that follows as auditable, interruptible, attributable steps — the kind a regulated buyer can actually defend. If the model is no longer the moat, this is what the moat looks like in code.
Get the latest product news and behind the scenes updates.