The AI-Native Engineering Playbook: How Small Teams Ship with Agents


AI-native engineering is not "prompt-and-pray" with a bigger model. The capability question is settled: models write production code, open pull requests, write the tests, and ask for review. The open question is whether your process can supervise output you didn't type. The scarce skill is no longer writing software; it is running a team of agents to ship systems that are reliable, scalable, debuggable, and self-healing.
This is the playbook we use to do exactly that, in plain English and faithful to the deck below. It is how a small AI-native team ships like a much larger one. Here is the whole thing as a scrollable deck, and the written breakdown follows.




From writing code to running a team
Yesterday's workflow was one developer, one chat window, copy-pasting snippets: fast to start, impossible to scale, with no memory between sessions and no record of why anything changed. Agentic engineering replaces it with four to six agents working in parallel against a shared spec, each scoped to its own slice of the codebase, every change logged and every plan reviewed before code is written. The output is a platform, not a script. If you have read what a single AI agent is and how agents work together, this is those ideas applied to your own codebase: the hard skill is no longer syntax, it is orchestration.
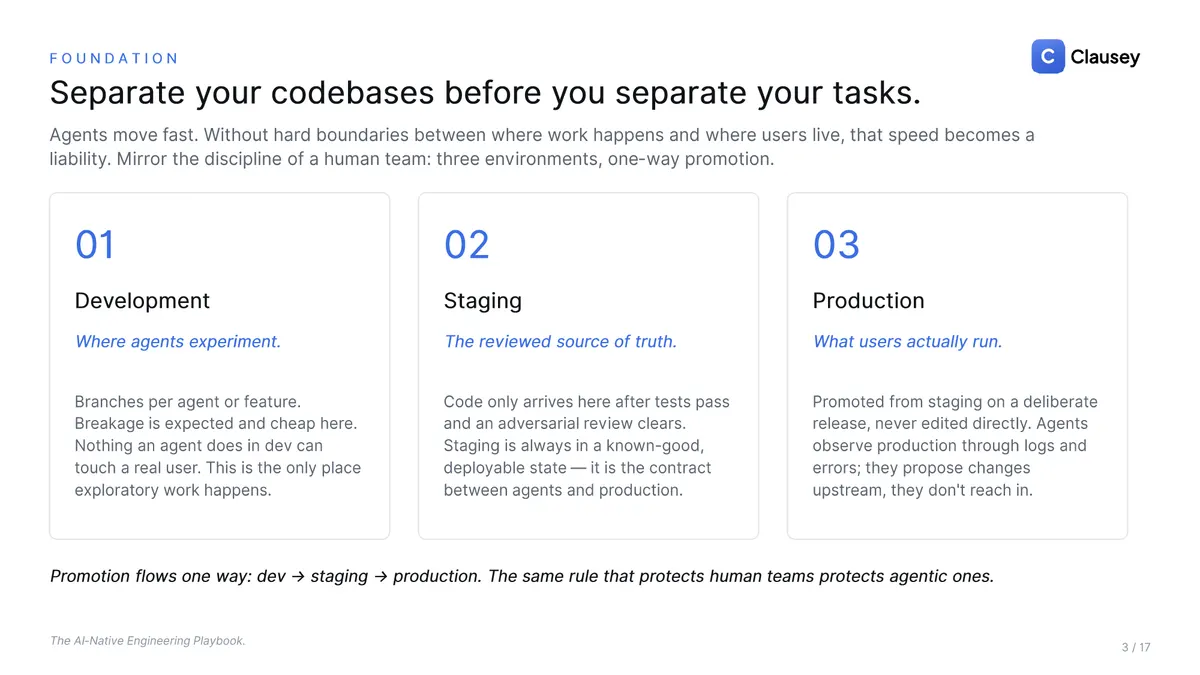
Separate your environments before you separate your tasks
Agents move fast, and without hard boundaries between where work happens and where users live, that speed becomes a liability. Mirror the discipline of a good human team: three environments, one-way promotion. Development is where agents experiment, a branch per agent or feature, where breakage is expected and cheap and nothing can touch a real user. Staging is the reviewed source of truth, where code arrives only after tests pass and an adversarial review clears, and it stays in a known-good, deployable state. Production is what users actually run, promoted from staging on a deliberate release and never edited directly; agents observe it through logs and errors and propose changes upstream, they don't reach in. Promotion flows one way: dev to staging to production. The rule that protects human teams protects agentic ones.
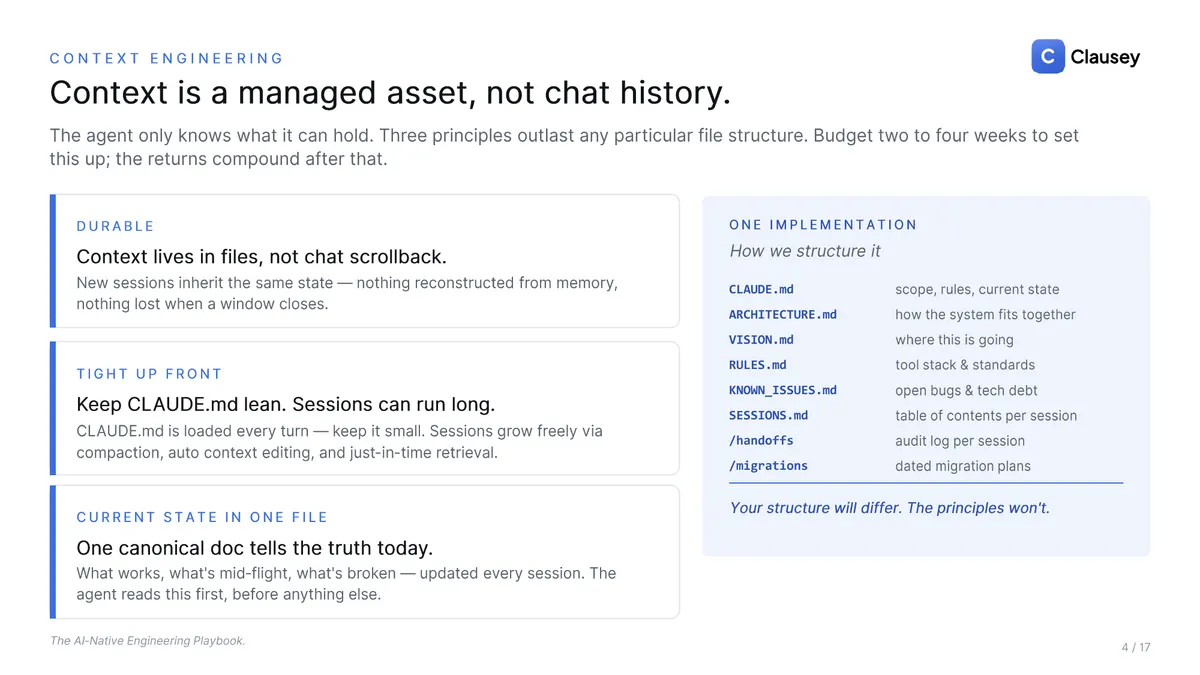
Context is a managed asset, not chat history
An agent only knows what it can hold, so treat context as something you engineer rather than something that accumulates. Keep it in files, not chat scrollback, so a new session inherits the same state and nothing is lost when a window closes. Keep the always-loaded instructions lean: a small, canonical document the agent reads first that says what works, what's mid-flight, and what's broken, updated every session, while the long work grows through compaction and just-in-time retrieval. Budget two to four weeks to set this up; the returns compound after that.
Make the agent an objective engineer, not an order-taker
The most valuable instruction you can write is not about formatting, it's about judgment. Tell the agent to build modular and to build for scale, to keep the stack uniform, and to explain the tradeoffs so you can decide, and, above all, to review your decisions and push back when you're wrong. Never write code blind. Plan first, forcing a design pass before any code, then run adversarial reviews: hand the plan to a fresh agent and tell it to attack the design and find what breaks, flagging each finding Critical, High, Medium, or Low. Run two to three passes and keep going until the Critical and High count reaches zero. Only then write the code.
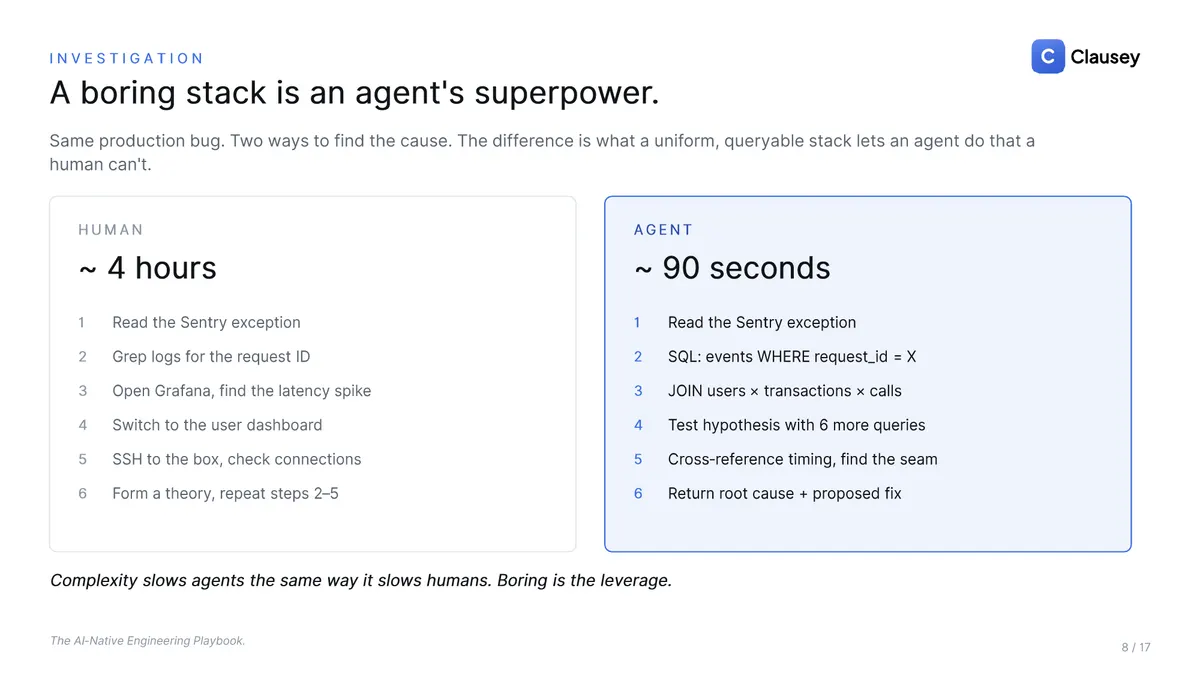
Keep the stack boring, and make it observable
Every tool you add is one more thing an agent must understand, query, and debug, so hold the stack uniform until scale genuinely forces a change. A boring stack is not a compromise, it's an agent's superpower. Default managed Postgres handles on the order of 2,000 events per second with no exotic tuning, and the ladder from there, a bigger instance and read replicas, then partitioning and sharding, carries you further than your roadmap will. OpenAI has described running ChatGPT on a single write Postgres with read replicas; the right shape of system goes a long way before it needs anything exotic. The investigation gap makes the point: on a uniform, queryable stack, a production bug that takes a human about four hours to chase across logs, dashboards, and SSH sessions takes an agent about ninety seconds of SQL and cross-referencing to root-cause. Complexity slows agents the same way it slows humans.
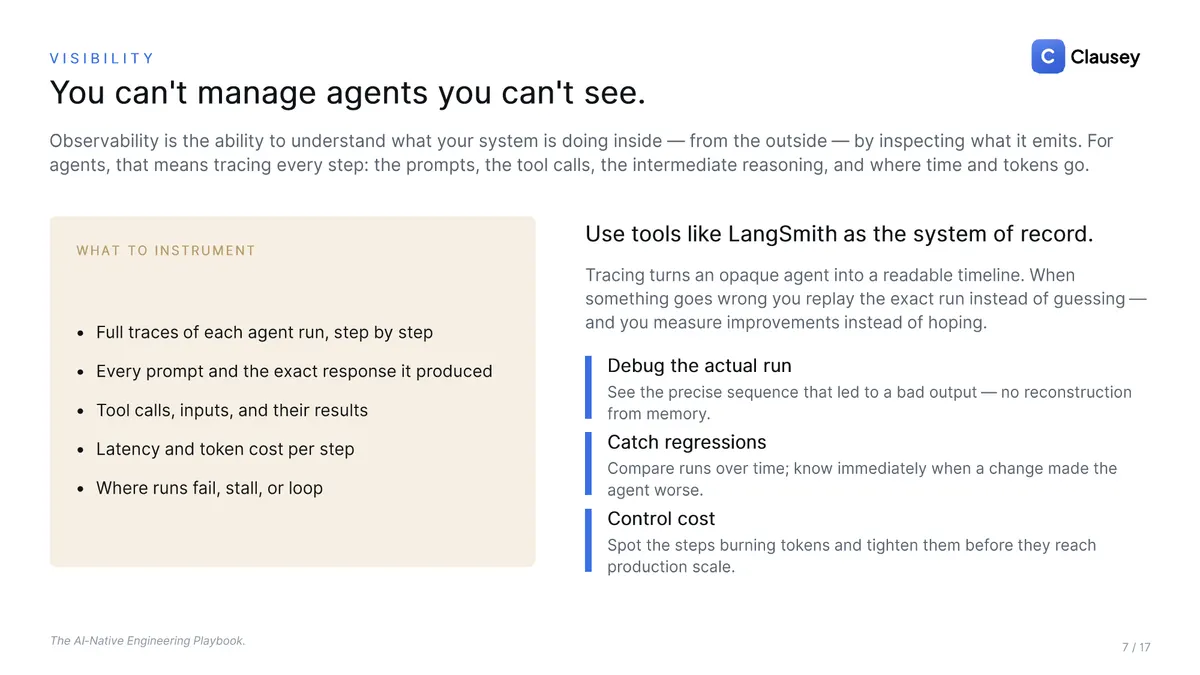
You can't manage what you can't see, so trace every run: the prompts, the exact responses, the tool calls and their results, and where time and tokens go. Tracing turns an opaque agent into a readable timeline. You debug the actual run instead of reconstructing it from memory, catch regressions by comparing runs over time, and find the steps burning tokens before they reach production scale.
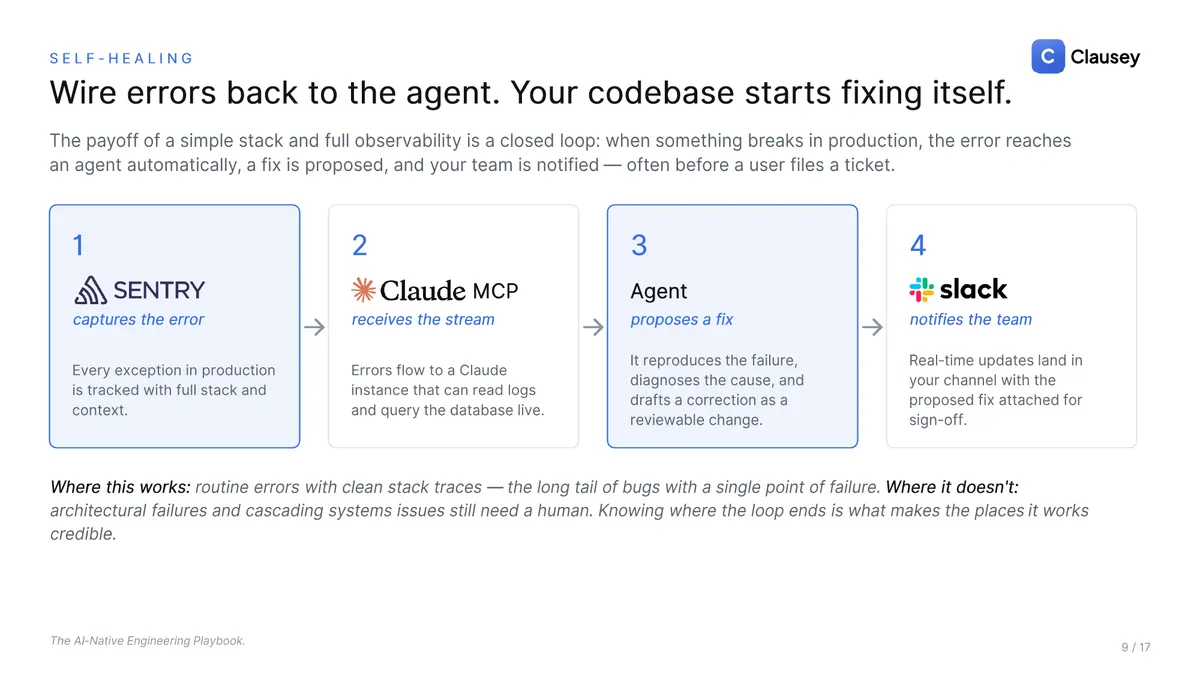
Wire errors back to the agent, and the codebase starts fixing itself
A boring stack plus full observability closes a loop. When something breaks in production, the error is captured, streamed to an agent that can read the logs and query the database live, diagnosed, and turned into a proposed fix as a reviewable change, and the team is notified, often before a user files a ticket. Be honest about the edges: this works for routine errors with clean stack traces, the long tail of single-point failures. Architectural failures and cascading systems issues still need a human. Knowing where the loop ends is exactly what makes the places it works credible.
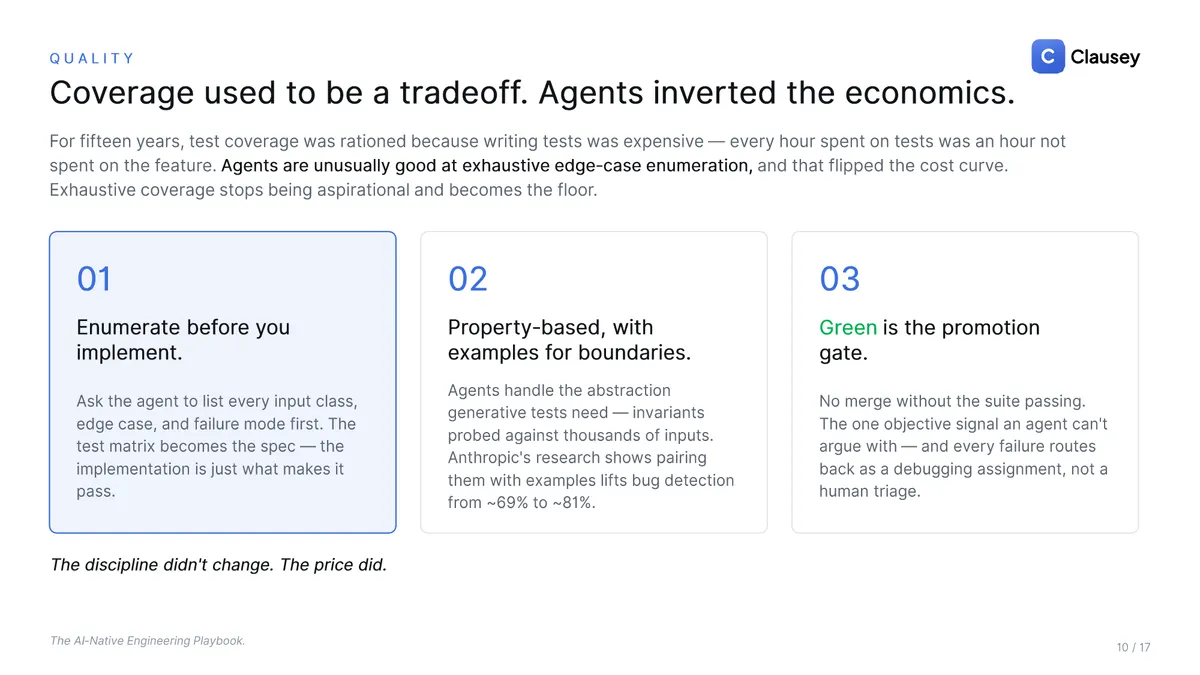
Coverage is the floor, not a tradeoff
For fifteen years, test coverage was rationed because writing tests was expensive: every hour on tests was an hour off the feature. Agents are unusually good at exhaustive edge-case enumeration, and that flipped the economics. Ask the agent to list every input class, edge case, and failure mode first; the test matrix becomes the spec, and the implementation is just what makes it pass. Use property-based tests for the boundaries; Anthropic's research shows that pairing them with concrete examples lifts bug detection from roughly 69% to 81%. Then make green the promotion gate: no merge without the suite passing, and every failure routes back to an agent as a debugging assignment, not a human triage queue.
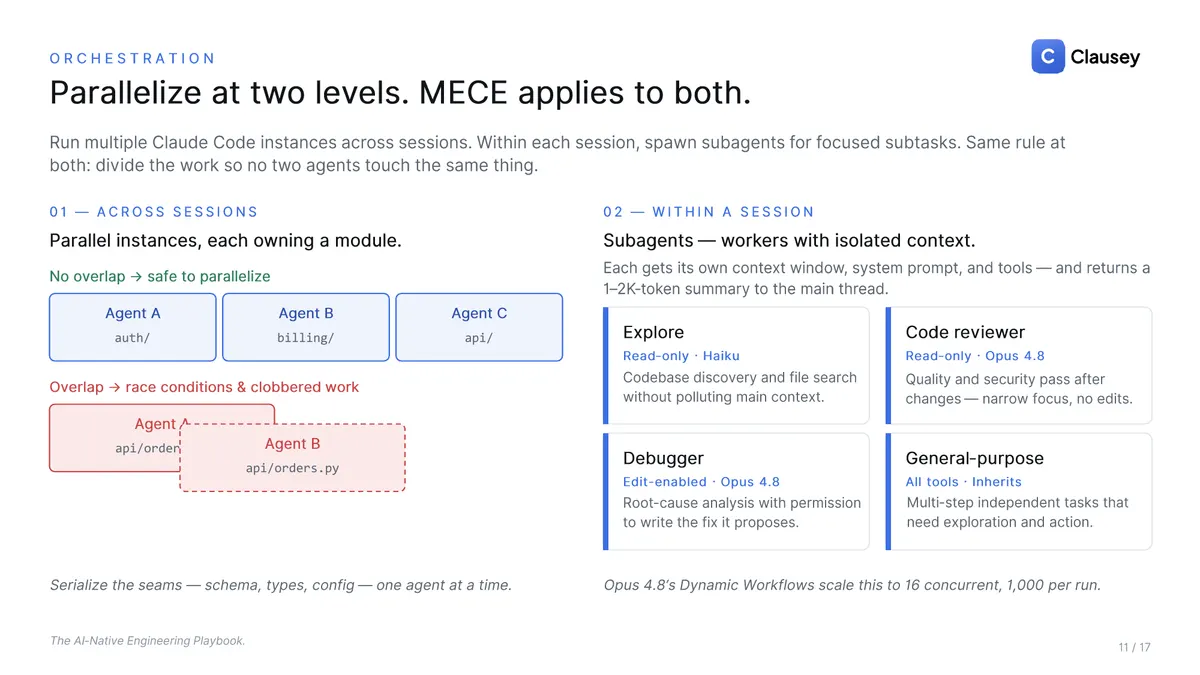
Parallelize the work, MECE at both levels
Parallelism runs at two levels. Across sessions, you run multiple agent instances, each owning a module, such as auth, billing, or api, with no overlap. Within a session, you spawn subagents with isolated context: an Explore agent on a cheaper model for read-only discovery, a code reviewer and a debugger on a stronger one, a general-purpose worker, each returning a small summary to the main thread. The single rule at both levels is MECE, mutually exclusive and collectively exhaustive: divide the work so no two agents touch the same thing, and serialize the seams, the schema, types, and config, one agent at a time, or you buy race conditions and clobbered work.
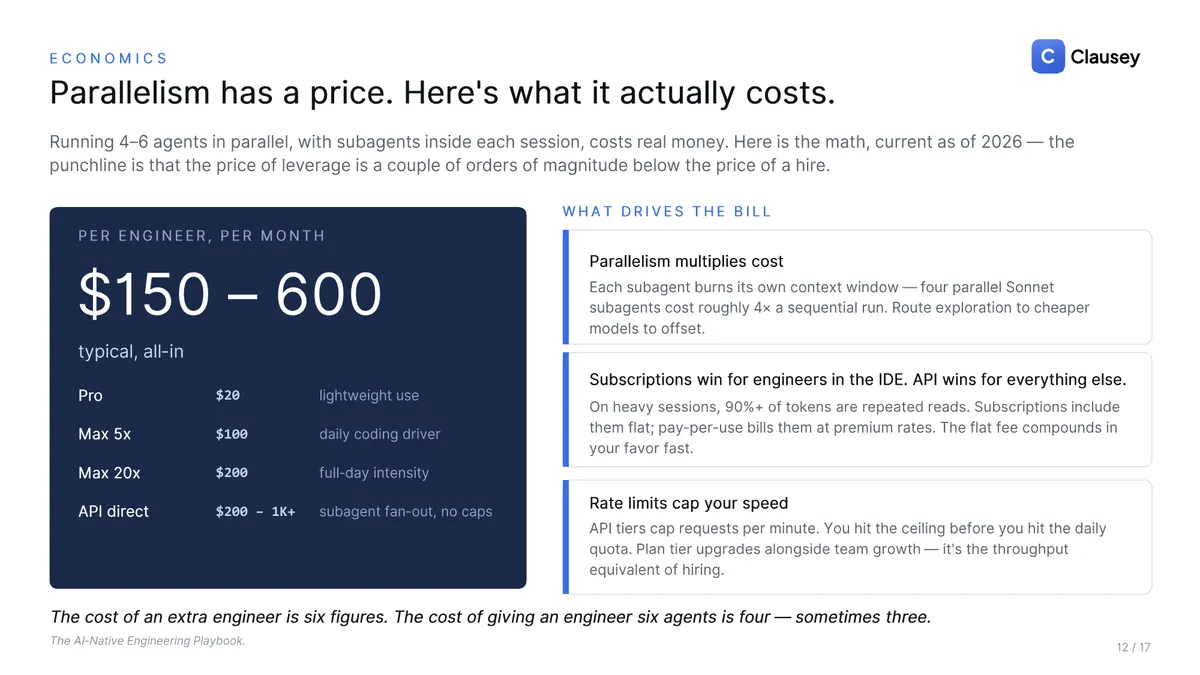
That leverage has a price, and it is the good kind. Running four to six agents with subagents inside each typically lands around $150 to $600 per engineer per month, because parallelism multiplies tokens and because flat subscriptions beat pay-per-use once most of your tokens are repeated reads. The cost of an extra engineer is six figures; the cost of giving an engineer six agents is four, sometimes three.
Wall off the agents, then keep them tidy
The same wiring that lets an agent fix production is a surface an attacker can manipulate, so defend in depth. Make least privilege the default: read-only tools, edit access scoped to specific paths, no direct production write ever, enforced at runtime and not merely in the prompt. Treat untrusted input as untrusted, because an error string, a log line, or a search result can carry a prompt injection; sanitize it before it enters context. And keep branch isolation with human merge. The wall that protects you from an agent's mistakes is the same wall that contains a compromised one.
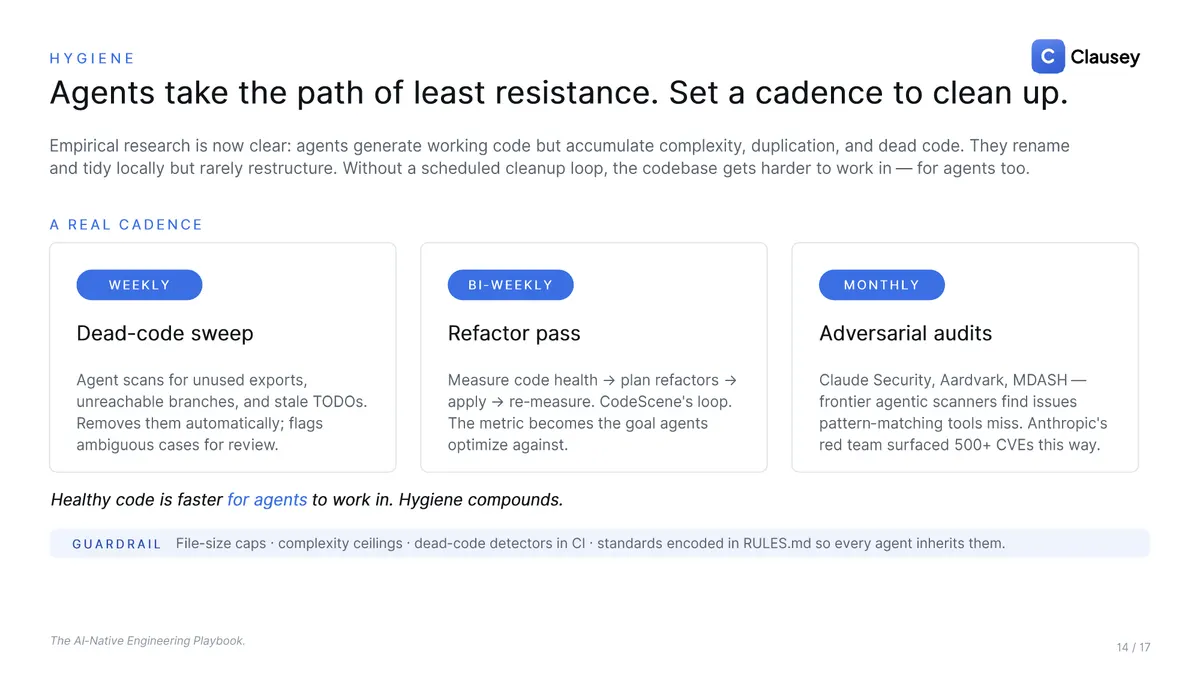
Then mind the entropy. Agents take the path of least resistance: they generate working code but accumulate duplication and dead code, tidying locally while rarely restructuring. Set a cleanup cadence, a weekly dead-code sweep, a regular refactor pass, and monthly adversarial audits with frontier security scanners, the kind of automated red-teaming that has surfaced hundreds of real CVEs. Encode the standards (file-size caps, complexity ceilings, dead-code detection in CI) into the rules every agent inherits, and healthy code stays fast to work in, for the agents too.
The job that stays human
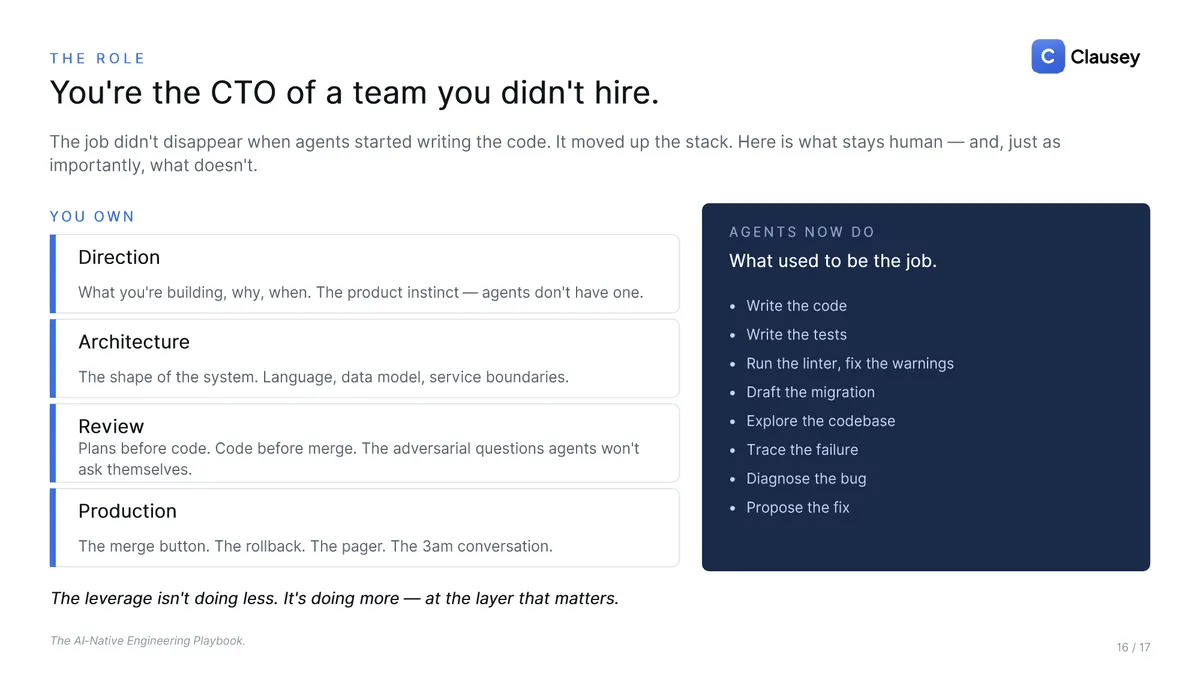
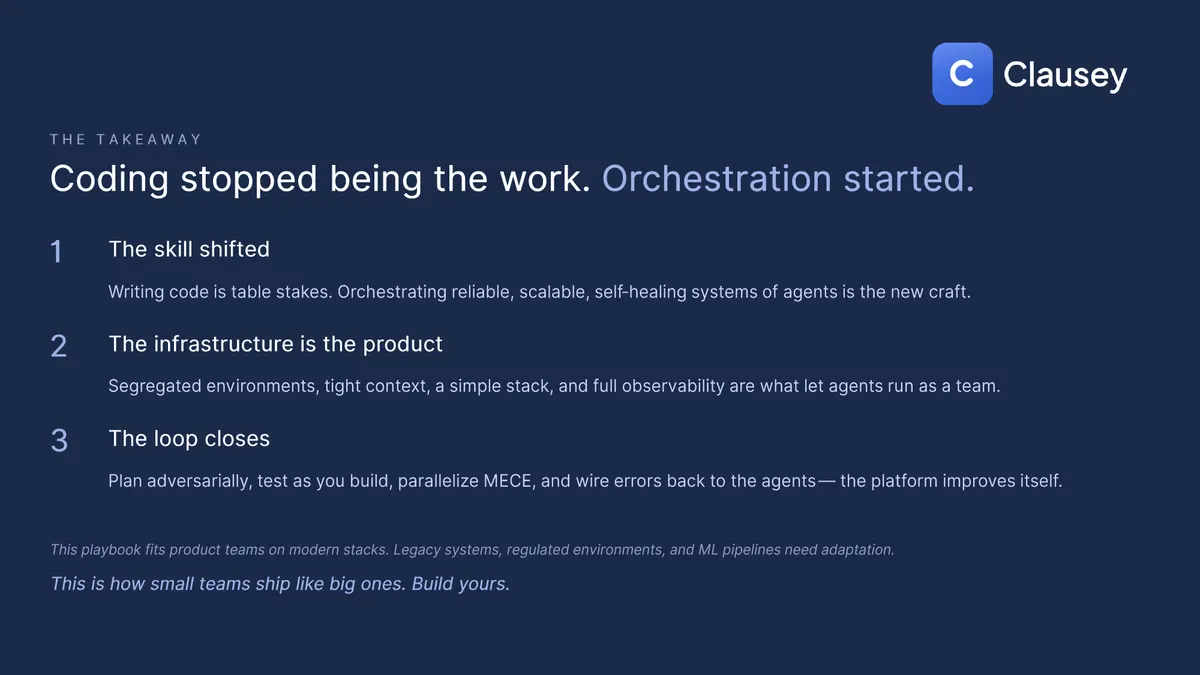
Add it up and the role didn't disappear when agents started writing the code; it moved up the stack. Agents now write the code and the tests, run the linter, draft the migration, explore the codebase, trace the failure, and propose the fix. You own direction (what you're building and why, the product instinct agents don't have), architecture (the shape of the system), review (the adversarial questions agents won't ask themselves), and production (the merge button, the rollback, the pager, the 3am call). The leverage isn't doing less; it's doing more, at the layer that matters. Coding stopped being the work. Orchestration started.
One honest caveat: this playbook fits product teams on modern stacks. Legacy systems, regulated environments, and ML pipelines need adaptation.
Where Clausey fits
We didn't write this from the outside. It is how Clausey is built: development, staging, and production with one-way promotion, a lean canonical context file, two to three adversarial review passes before any migration, a deliberately boring Postgres stack, traced agent runs, and MECE parallel sessions. It is also what Clausey is. We point the same orchestration at your operations instead of ours: an agent platform that reads your documents, structures them into data, answers questions with citations, checks everything against your policies, and automates the work that follows.
This is how small teams ship like big ones.
Get the latest product news and behind the scenes updates.